사전 학습된 BERT를 사용하는데 따르는 문제는 계산 비용이 많이 들고 제한된 리소스로 모델을 실행하기가 매우 어렵다는 것이다. 사전 학습된 BERT는 매개변수가 많고 추론에 시간이 오래 걸려 휴대폰과 같은 edge 디바이스에서 사용이 어렵다.
즉, 상용화 레벨에서는 BERT를 바로 사용하는 것은 쉽지 않다.
지식 증류 : 소금물에서 증류하여 소금을 얻어내듯이, 지식 증류(knowledge distilation)는 커다란 Teacher 모델에서 엑기스만 뽑아내어 작은 Student 모델로 전달하는 방식.
5.1 지식 증류 소개
- 지식 증류 : 사전 학습된 모델의 동작을 재현하기 위해 소형 모델을 학습시키는 모델 압축 기술.
- 교사-학생 학습(teacher-student learning)이라고도 함. 사전 학습된 대형 모델은 교사, 소형 모델은 학생

- 문장 내 다음 단어를 예측하는 태스크로 사전학습, 단어 5개에 대한 확률 분포가 출력되었다고 가정해보자
- 이 결과로 인해 본질적으로 확률이 가장 높은 homwork를 선택하게 될것이다.

- 하지만 확률 분포에서 확률이 가장 높은 선택 하는 것 외에도 다른 유용한 정보를 추출할 수 있다.
- 바로 암흑 지식(dark knowledge)이다.
- 다음 그림을 보면 homework라는 단어 외에 다른 단어에 비해 확률이 높은 단어가 있음을 알 수 있다.
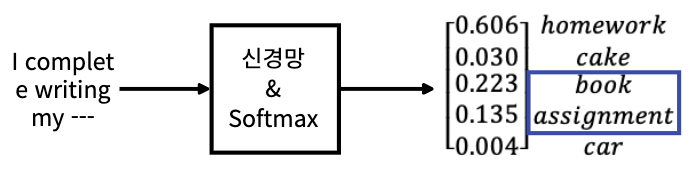
- 지식을 증류하는 동안, 우리는 학생 네트워크가 교사로부터 이 암흑 지식에 대해서도 배우길 원한다.
- 하지만 일반적으로 성능이 좋은 모델은 정답 클래스의 경우 1에 가까운 높은 확률을 반환하고, 이외에 다른 클래스의 경우 0에 가까운 확률을 반환하게 된다.
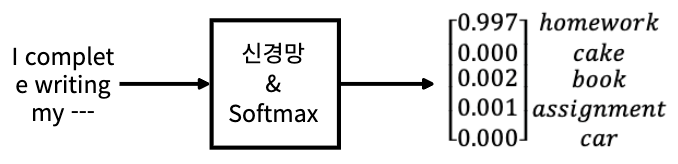
- 이러한 확률 분포에서 그대로 암흑 지식을 추출할 수 없음
- 이러한 경우 Temperature와 함께 Softmax를 사용하여 확률 분포를 평활화 시켜 문제점을 해결한다.

- $P_i$는 각 클래스에 대한 확률값 , T는 Temperature
- T=1로 설정하면 일반적인 Softmax 함수, T의 값을 증가시킬수록 확률분포가 더 평활해짐.
- 즉 T의 값을 늘림으로써 다른 클래스에 대한 더 많은 정보를 제공하는 평활 확률 분포를 얻게 된다.

- 결과적으로 Temperature에 대한 Softmax 함수를 통해 암흑 지식을 얻을 수 있다.
- 그런 다음 지식 증류를 통해 암흑 지식을 교사로부터 학생에게 전달한다.
5.1.1 학생 네트워크 학습
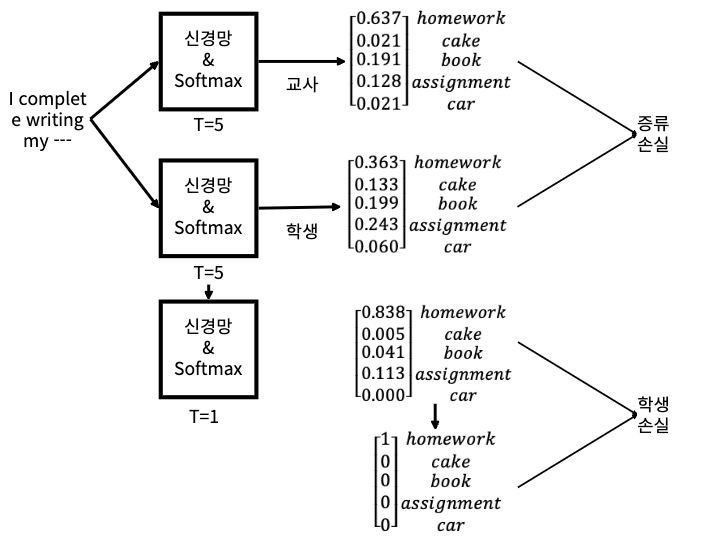
- 이제 위 과정에서 교사 네트워크를 사전 학습 한 것을 학생 네트워크로 전달하는 방법을 알아 보자.
- 다음 그림과 같이 입력 문장을 교사, 학생 네트워크에 공급하고 확률 분포를 출력한다.
- 교사 네트워크로부터 얻는 출력을 소프트 타깃(soft target), 학생 네트워크에서 만든 예측을 소프트 예측(Soft prediction)이라고 함.

- 이제 소프트 타깃과 소프트 예측 간의 교차 엔트로피 손실(증류 손실/distillation loss)을 계산하고, 손실을 최소화하기 위한 역전파로 학생 네트워크를 학습시킨다.
- 또한 T의 값은 교사 학생 모두 동일한 값으로 유지, 1보다 큰 값으로 설정한다.
- 학생 네트워크에서는 증류 손실과는 별도로 학생 손실이라는 손실을 하나 더 사용한다.
- 그전에 하드 타켓과 소프트 타겟의 차이를 이해할 필요가 있다.
소프트 타겟 : 교사 네트워크에서 반환된 확률 분포를 직접 취함. 즉, T가 1보다 큰 softmax에서 예측한 확률 분포
소프트 예측 : 학생 네트워크에서 T가 1보다 softmax로 예측한 확률 분포
하드 타겟 :해당 확률 분포 내에서 확률이 가장 높은 곳에 1을 설정하고, 나머지 값에 대해서 0을 설정한 확률 분포
하드 예측 : 해당 네트워크에서 T를 1로 지정한 softmax로 예측한 확률 분포. 즉, 일반적인 소프트맥수 함수 예측.
- 학생 손실은 하드 타깃과 하드 예측 간의 교차 엔트로피 손실이다.
1. 학생 손실을 얻기 위해 우선 학생 네트워크의 하드 예측을 얻는다.
2. 그리고 레이블 데이터(정답)를 기반으로 하드 타겟을 얻는다.
3. 그런 다음 하드 예측과 하드 타깃간의 교차 엔트로피로 학생 손실을 계산한다.
- 최종 손실 함수는 학생 손실과 증류 손실의 가중 합계이다.
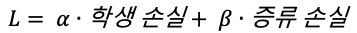
- 알파와 베타는 학생 및 증류 손실의 가중 평균을 계산하는데 사용되는 하이퍼 파라미터이다.
- 위의 손실 함수 값으 최소화 하는 방법으로 학생 네트크를 학습시킨다.
5.2 DistilBERT : BERT의 지식 증류 버젼
Abstract
- 최근 BERT를 포함한 많은 NLP 분야에서 큰 사이즈의 pre-trained 모델을 많이 사용하고 있다.
- 하지만 이러한 큰 모델들은 학습과, 추론(inference) 과정에서 큰 비용과 리소스가 필요하다는 한계가 있다.
- DistilBERT를 제안함. 작고 빠르고 가벼운 BERT 버젼.
- DistilBERT는 pre-train된 대형 BERT(교사 BERT)에서 지식 증류를 하여 소규모 BERT로 이전하는 방식이다.
- DistilBERT는 대형 BERT 모델에 비해 60% 더 빠르며 크기는 40% 더 작다.
Knowledge distillation(위에 자세히 설명하였으므로 요약해서 설명)
- 지식 증류(knowledge distillation)은 큰 사이즈의 모델의 동작을 재현하는 압축된 작은 사이즈의 모델을 훈련시키는 기술.
- 일반적으로 잘 학습된 모델은 올바른 class에 높은 확률을, 그렇지 않은 class에는 0에 가까운(near-zero) 확률을 가진다.
- 본 논문에서는 near-zero의 확률을 가지는 클래스들 역시 모델의 일반화 능력에 큰 영향을 미친다고 주장하며, 가장 큰 확률의 클래스 이외에 다른 클래스에 비해 확률이 높은 클래스를 '암흑 지식'이라고 한다.
- 따라서 확률 분포에서 다양한 클래스에 대한 정보를 제공하기 위해 Temperature를 사용한 Softmax를 사용한다.
- T가 더 커질수록 확률 분포가 더 부드러워 진다.
DistilBERT: a distilled version of BERT
Student architecture
- DistilBERT 즉, 학생 BERT는 사전 학습을 받지 않았다. 교사 BERT로부터 배워야 한다.
- 지식 증류 학습의 경우 RoBERTa처럼 MLM 태스크만 사용해 학생 BERT를 학습시킨다.
- 따라서 token type embedding(segment embedding), 마지막 pooler도 제거한다.
- 그리고 layer 수 역시 절반으로 줄인다.
Distillation
- 지식 증류 학습의 과정은 다음과 같다.
1) 마스크된 문장을 교사 BERT와 학생 BERT에 입력으로 제공하고 어휘 사전에 대한 확률 분포를 출력으로 얻는다.

2) 소프트 타깃과 소프트 예측 사이의 교차 엔트로피 손실로 증류 손실($L_{ce}$)을 계산한다.
- $t_i$ : 교사 BERT의 출력(소프트 타켓), $S_i$ : 학생 BERT의 출력(소프트 예측)
$$L_{ce}=\sum_i{t_i *\log{(s_i)}}$$
3) 하드 타깃과 하드 예측 사이의 교차 엔트로피 손실로 MLM 손실(학생 손실 $L_{MLM}$)을 계산한다.
일반적인 MLM 태스크에서 실제값(하드 타겟)에 소프트맥스를 거친 예측값(하드 예측)간의 loss를 줄이기 위한 것이므로 학생 손실은 즉 MLM 손실이라고 할 수 있다.
4) 마지막으로 교사와 학생 모델의 hidden 상태 벡터들을 같은 방향을 바라보게 하는 cosine embedding loss($cosine embedding loss$)를 계산한다.

- 위 그림은 ELMo, original BERT와 DistilBERT를 GLUE로 성능을 비교했다. 9가지 task의 평균 성능은 BERT-base와 DistilBERT가 모두 ELMO보다 훨씬 좋은 수치를 보여주었다.
- DistilBERT는 BERT-base에 비해 2.5% 낮은 성능을 달성했다.
Conclusoin
결론적으로 DistilBERT는 original BERT에 비해 40% 작고, 60% 빠르면서, 97% 정도의 성능을 제공한다.
5.3 TinyBERT 소개
- TinyBERT도 DistilBERT와 마찬가지로 사전 훈련된 대규모 모델을 사용하는데 많은 리소스가 들기 때문에 엣지 디바이스에서 효율적으로 사용하기 어렵다는 문제점을 제기함.
- 그렇기 때문에 본 논문에서는 정확성을 유지하면서 속도는 빠르고 경량화를 하기 위해 지식 증류(Knowledge Distillation)방법을 사용하였으며, 특히 Transformer 기반의 모델에 유효한 새로운 Knowledge Distillation 기법을 제안하였다.
- 그 결과 TinyBERT는 BERT_base보다 7.5배 작고 9.4배 빠른 모델이 됨.
- 또한 TinyBERT는 Transformer Distillation을 사전학습단계(general-domain)와 task-specific(Fine-Tuning)단게에서 둘 다 진행된다.
- 즉, TinyBERT는 pre-train 단계의 지식 뿐만 아니라 task-specific 지식까지 학습하게 된다.
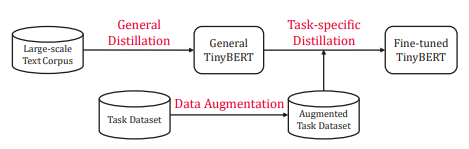
5.3.1 Teacher-Student Architecture
- 교사, 학생 BERT는 기본적으로 입력 문장의 문맥 관계를 학습 및 표현벡터를 반환하는 인코더, 표현 벡터를 예측하는 FFNN으로 이루어져 있다.
- 교사 BERT. 즉, BERT-base 모델은 12개의 인코더 레이어와 12개의 어텐션 헤드로 구성되어 있으며, 표현 벡터 크기는 768이다. (총 1억1천만개의 파라미터로 구성되어 있다.)
- 학생 BERT의 경우 4개의 인코더 레이어와 FFNN, 표현 벡터 크기는 312개로 총 1,450만 개의 파라미터를 가지고 있다.
5.3.2 TinyBERT 지식 증류
- TinyBERT의 경우 DistilBERT와 달리 교사의 출력 레이어에서 학생 BERT로 지식을 전달하는 것 외에도 다른 레이어의 지식도 전달한다.
- 다음 수식은 매핑함수 g를 사용해 교사 BERT의 n번째 레이어에서 학생의 m번째 레이어로 지식을 전달한다는 것을 의미한다.
$$ n = g(m)$$
매핑 함수 라는 것은 다른 값으로 대응 시키는 함수를 의미한다.
즉, 학생의 Layer의 값을 교사 Layer로 대응시키는 것.
그렇기 때문에 함수 g가 교사 레이어가 아닌 학생 레이어에 씌워진 것.
- TinyBERT의 Transformer distilation에서는 세가지 레이어에 지식을 전달하여 다음의 표현을 학습하도록 한다.
1. 트랜스포머 레이어 (인코더 레이어)
2. 임베딩 레이어(입력 레이어)
3. 예측 레이어(출력 레이어)
Transformer Layer Distillation
- Transformer Layer에서는 attention과 hidden state 각각에 대해 지식을 distillation한다.
Transformer레이어는 기본적으로 인코더 레이어.
인코더 레이어에서 멀티 헤드 어텐션을 사용해 어텐션 행렬을 계산,
인코더 레이어가 은닉 상태의 표현 벡터를 출력으로 반환함.
- 따라서 Transformer Layer Distillation에는 두가지 distillation이 포함된다.
- 어텐션 기반 증류(attention-based distillation)
- 은닉 상태 기반 증류(hidden state-based distillation)
Attention-based distillation
- 어텐션 기반 증류를 수행하는 이유는 다음과 같다.
어텐션 행렬에는 언어 구문, 상호 참조 정보 등과 같은 유용한 정보가 포함되어 있어 일반적으로 언어를 이해하는데 매우 유용하다.
- 어텐션 기반 증류를 수행하기 위해 학생의 어텐션 행렬과 교사 BERT의 어텐션 행렬 간의 평균 제곱 오차를 최소화해 학생 네트워크를 학습시킨다.
- 어텐션 기반 증류 손실 $L_{어텐션}$은 다음과 같다.
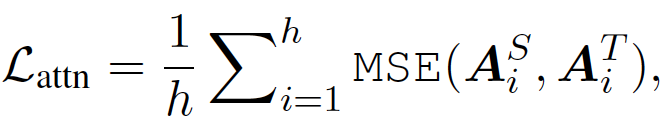
h : attention head 개수
$A_i^T$ : 교사 모델의 i번째 head가 생성한 어텐션 행렬
$A_i^S$ : 학생 모델의 i번째 head가 생성한 어텐션 행렬
MSE : 평균 오차 제곱
- 여기서는 Softmax를 취하지 않은, 즉 정규화되지 않은 어텐션 행렬 $A_i$를 사용하는데, 본 논문에서는 시험을 해보았을때 정규화되지 않은 어텐션 행렬을 목표로 할 때 더 빠르게 수렴하고 성능이 괜찮았기 때문이라고 한다.

- 다음 그림은 Attention-based Distillation를 보여준다.

Hidden State-based distillation
- 이제 Hidden State는 기본적으로 인코더의 출력, 즉 표현 벡터다.
- 따라서 Hidden State-based distillation를 수행하기 위해 교사 인코더의 은닉 상태와 학생 인코더의 은닉 상태 간의 평균 제곱 오차를 최소화해 증류를 수행한다.
- 수식은 다음과 같다.
$$L_{은닉} = MSE(H^S, H^T)$$
- 학생 $H^S$와 $H^T$의 은닉 상태 차원은 다양할 것이다.
- 게다가 교사 BERT는 기본적으로 BERT-base이고, 학생 BERT는 TinyBERT이므로 교사 BERT의 차원수는 학생 BERT의 차원보다 항상 클것이다.
- 따라서 학생,교사 은틱 상태를 같은 차원수로 변환하기 위해 학생 은닉 상태 $H^S$에 행렬을 곱해 선형 변환을 수행한다.
$$L_{은닉} = MSE(H^SW_h, H^T)$$

Embedding Layer Distillation
- Embedding Layer Distillation에서는 교사의 임베딩 레이어에서 학생의 임베딩 레이어로 지식을 전달한다.
- 교사-학생의 임베딩 레이어 차원은 다르기 때문에 hidden state-based distillation과 유사하게 학생의 임베딩 $E^S$에 $W_T$를 곱해 차원수를 같게 한다.
$$L_{임베딩} = MSE(E^SW_e, E^T)$$
$E^S$ : 학생 BERT의 임베딩 결과
$E^T$ : 선생님 BERT의 임베딩 결과
Prediction Layer Distillation
- Prediction Layer Distillation은 교사 BERT가 생성한 최종 출력 레이어의 지식을 학생 모델에 전달한다.
- 이 과정은 DistilBERT에서 배운 증류 손실과 유사하다.
- 소프트 타깃과 소프트 예측 간의 교차 엔트로피 손실을 최소화해 예측 레이어 종류를 수행한다.
$$L_{예측} = CE(Z^T/t, Z^S/t)$$
Z^T, Z^S : 교사,학생 BERT에서 생성한 최종 출력 레이어(예측 확률 분포)
t : temperature value, 본 논문에서는 t=1로 둘때 가장 잘 작동한다고 함.
CE : Cross Entropy Loss
최종 손실 함수
- 지금 까지 나온 distillation loss을 포함해 최종 loss는 다음과 같이 정리할 수 있다.
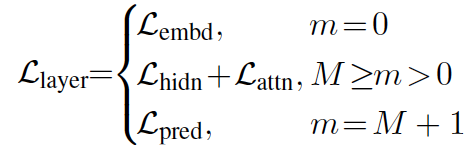
5.3.4 TinyBERT 학습
- TinyBERT에서는 다음과 같이 2단계 학습을 한다.
- 일반 증류(General Distillation)
- 태스크 특화 종류(task-specific distillation)
General Distillation
- 기본적으로 사전 학습 단계를 의미.
- 사전 학습된 대형 BERT(BERT-base)를 교사로 사용하고, 증류를 수행해 지식을 작은 학생 BERT(TinyBERT)에게 전달.
- 모든 레이어(인코딩, 임베딩, 예측)에 증류를 적용.
- 증류 후 학생 BERT는 교사의 지식으로 구성되며 일반 TinyBERT라고 부른다.
Taks-Specific Distillation
- 간단히 말하면 파인 튜닝.
1. 사전 학습된 BERT-base 모델을 사용해 특정 태스크에 맞게 파인 튜닝/ 이 파인 튜닝된 BERT-base를 교사로 사용.
2. Fine-Tuning된 BERT-base의 지식을 일반 TinyBERT로 증류.
3. 증류 후 일반 TinyBERT는 학생 BERT이며, 이를 파인 튜닝된 TinyBERT라고 부를 수 있다.
- 파인 튜닝 단계에서 증류를 수행하려면 일반적으로 더 많은 데이터셋이 요구된다.
- 그렇기 때문에 본 논문에서는 DataAugmentation(데이터 증식)을 제안했다.
Data Augmentation
- 사전학습된 BERT 모델과 GloVe 워드 임베딩을 사용하여 토큰 단위의 대체를 통해 데이터 증축을 실행한다.
1. 입력 문장을 토큰화 하여 X라는 리스트에 토큰을 저장한다.
2. X_masked라는 다른 리스트에 X를 복사한다.X = [Paris,is,a,beautiful,city]
X_masked = [Paris,is,a,beautiful,city]3. X[i]가 단일 단어인지 확인한다.
case 1)true
- [MASK]토큰으로 X_masked[i]를 마스킹한다.
- BERT-base를 사용해 마스크된 단어를 예측한다.
- 가장 가능성이 높은 K개의 단어를 예측하여 candidates라는 리스트에 저장한다.
case 2)false
- 마스킹하지 않고 그대로 둔다.
- 대신 GloVe 임베딩을 사용해 X[i]와 가장 유사한 단어 K개를 확보하고 candidates 리스트에 저장한다.
4. 균일 분포에서 p를 무작위로 추출하고, $p_t$(임계값)를 지정한다.
case 1)p <= $p_t$
- X_masked[i]를 후보 목록의 임의의 단어로 교체한다.
case 2)p > $p_t$
- X_masked[i]를 실제 단어인 X[i]로 둔다.
이렇게 모든 문장 N개에 대해 N번 반복한다.
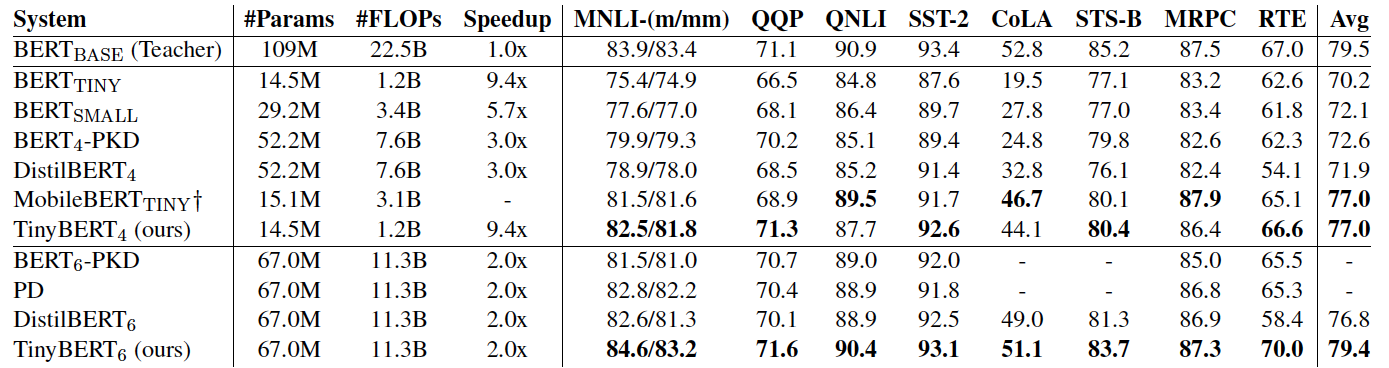
- TinyBERT는 BERT-base 모델보다 7.5배 더 작으며, 동등한 성능을 가짐.
5.4 BERT에서 신경망으로 지식 전달
https://arxiv.org/abs/1903.12136
Distilling Task-Specific Knowledge from BERT into Simple Neural Networks
In the natural language processing literature, neural networks are becoming increasingly deeper and complex. The recent poster child of this trend is the deep language representation model, which includes BERT, ELMo, and GPT. These developments have led to
arxiv.org
- 본 논문은 BERT에서 태스크 특화 지식을 단순 신경망으로 추출하는 흥미로운 논문이다.
- 본 논문에서도 대규모 신경망 모델들은 리소스가 제한된 시스템에서 배포가 불가능하다는 문제점을 제시하였다.
- 그렇기 때문에 BERT-large 모델을 해당 다운 스트림 태스크에 대해 파인 튜닝하여 교사 BERT로 사용하고
- 교사 BERT의 지식을 더 얕은 신경망 구조인 BiLSTM(단순한 양방향 LSTM)모델로 전달하는 방법을 제시하였다.
학생 네트워크
-학생 네트워크의 구조는 태스크에 따라 변경된다.
1) 단일 문장 분류 작업의 경우
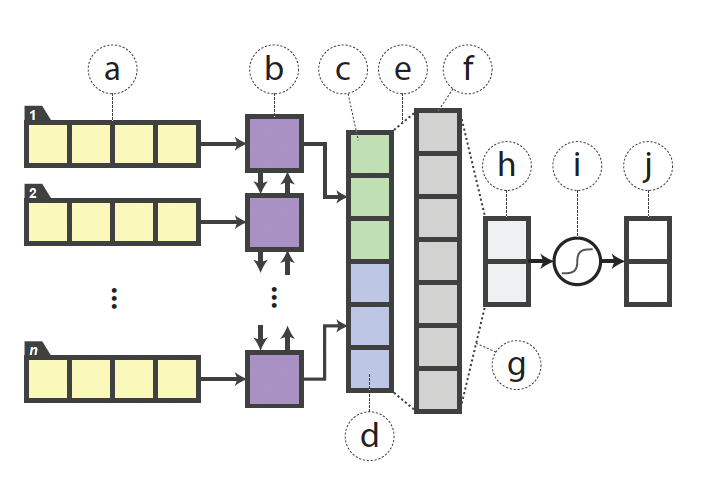
- "I love Paris"라는 문장을 입력으로 받았을때 긍정인지 부정인지 분류하는 태스크라고 할 수 있다.
1. 먼저 문장의 임베딩을 얻은 다음 양방향 LSTM에 공급한다.
2. 양방향 LSTM은 양방향으로 문장을 읽게 되고, 순방향 및 역방향 은닉 상태를 얻게 된다.
3. RELU 활성화 함수를 사용해 순방향 및 역방향 은닉 상태를 FFNN에 공급한다.
4. FFNN에서 다음 로짓을 출력으로 반환
5. 로짓을 소프트맥스 함수에 입력, 긍정 부정에 대한 문장의 확률을 얻는다.
2) 한쌍의 문장을 사용하는 태스크인 경우
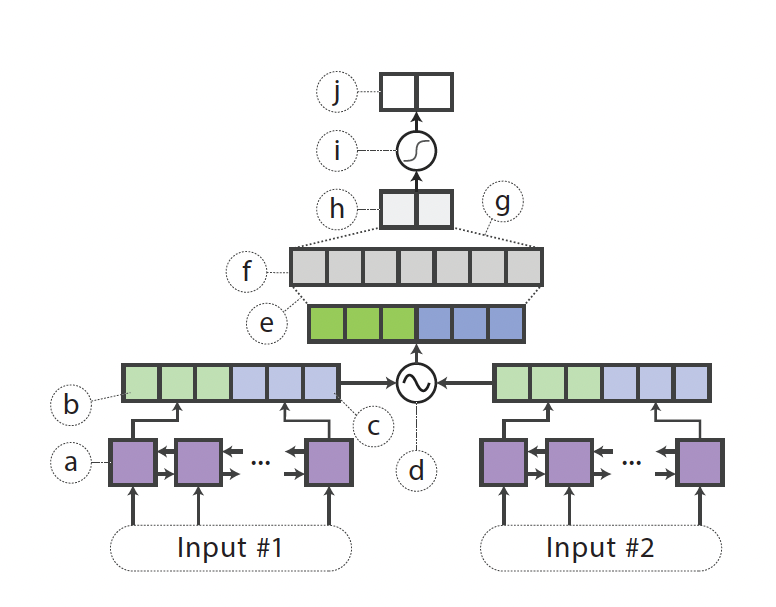
- 문장 매칭 태스크와 같이 두 문장이 유사한지 분류하는 태스크이다.
- 이 경우 학생 네트워크는 샴(siamese)BiLSTM이다.
1. 두 문장의 임베딩을 얻은 다음 두 BiLSTM에 공급한다.
2. 샴 구조로 두 BilSTM의 가중치를 공유해서 문장 표현 벡터($h_{s1},h_{s2}$)를 생성한다.
3. 수식과 같은 연결 비교 연산을 사용해 $h_{s1},h_{s2}$를 결합한다.
- 학생 네트워크는 학생 손실 $L_{학생}$과 증류 손실 $L_{증류}$의 가중 합계 손실을 최소화하는 방향으로 학생 네트워크를 학습시킨다.
$$L = aL_{학생} + BL{종류}$$
- B의 값을 $1-a$로 지정하면 다시 다음과 같이 작성할 수 있다.
$$L = aL_{학생} + (1-a)L{종류}$$
- 여기서 증류 손실은 소프트 타깃과 소프트 예측 간의 평균 제곱 손실을 사용한다.
Data Augmentation for Distillation
- 증류 접근법에서, 작은 데이터셋으로는 교사 모델이 지식을 완전히 표현하기에 부족할 수 있다.
- 그래서 데이터 셋 크기를 늘리기 위해 태스크 독립적인 데이터 증식(task-agnostic data augmentation)방법을 사용한다.
- 태스크 독립적인 데이터 증식을 수행하기 위해 다음과 같은 방법을 사용한다.
1. 마스킹
2. 형태소(parts of speech POS) 기반 단어 대체
3. 엔그램(n-gram) 샘플링
1) 마스킹
- $P_{mask}$ 확률로 문장의 단어를 [MASK]로 교체후 마스크된 토큰으로 새 문장을 만든다.
- 이를 통해 레이블에 대한 각 단어의 기여도를 명확하게 한다.
긍정,부정 감정 분석 테스크에서
"I [MASK] the comedy" 문장이 긍정일 확률. 즉, 신뢰도가 "I love the comedy"문장보다 떨어진 logit을 도출할 것이다.
반면 "I love [MASK] comedy"의 경우 "the"라는 단어의 기여도가 크지 않으므로 신뢰도가 크게 떨어지지 않을것이다.
2) POS-guided word replacement(형태소 기반 단어 대체 방법).
- $P_{pos}$ 학률로 문장의 한 단어를 다른 단어로 대체하지만, 같은 품사로 대체한다.
"What do pigs eat" 를 "How do pigs eats"로
3) n-gram sampling
- n-gram : n개의 연속적인 단어 나열을 의미
- P_{ng}$의 확률로 문장에서 엔그램을 무작위로 샘플링하는 방법.
- 좀더 과격하게 마스킹을 하는것과 같다.
데이터 증식 프로세스
- 입력 문장내에 있는 단어들을 ${w_1,w_2,...,w_3,...w_n}$라고 하자
- 균일 분포 $x_i~Uniform(0,1)$를 사용해서 $w_i$를 추출한다.
case 1 $x_i < P_{mask}$
- $x_i$에 마스킹을 적용한다.
case 2 $P_{mask}<x_i < P_{mask}+P_{pos}$
- $x_i$에 POS-guided를 적용한다.
* 마스킹 및 형태소 기반 단어 로직은 서로 겹치지 않는다. 즉, 하나를 적용하면 다른 하나는 적용할 수 없다.
- 이 단계 후 수정된(합성된)문장을 얻게 된다.
-확률 $P_{ng}$로 n-gram 샘플링을 전체 합성 예제에 대해 적용한다.
- 마지막으로 합성 예제는 라벨링 되지 않은 확장된 데이터셋(data_aug)에 추가한다.
문장이 하나인 경우
- N번 수행하여 N개의 새로운 합성 문장을 얻는다.
문장이 쌍인 데이터 샘플
- 앞의 문장에만 적용
- 뒷 문장에만 적용
- 두 문장 모두 적용
'책 정리 > 구글 Bert의 정석' 카테고리의 다른 글
| 8-2 장. domain-BERT(ClinicalBERT) (0) | 2023.02.15 |
|---|---|
| 8-1 장. sentence-BERT (0) | 2023.02.14 |
| 4.4장-Span BERT (0) | 2023.02.01 |
| 4-3장. ELECTRA (1) | 2023.02.01 |
| 3장. BERT 활용하기 (2) | 2023.01.31 |



