1. Sentence-BERT
- BERT의 파생 모델로, 주로 문장 표현을 계산하는데 사용된다.
- 기존의 BERT 모델에서 문장의 표현을 얻기 위해서는 막대한 추론 시간이 걸린다.
- 본 논문에서는 10,000개의 문장 모음에서 BERT 모델을 사용해서 가장 유사한 쌍을 찾으려면 최대 65시간이 필요하다 라고 하였다.
- sentence-BERT를 사용하게 된다면 추론 시간은 크게 줄어들게 될것이다.

1.1 문장 표현 계산
- 기존의 문장 표현을 계산하는 방법을 생각해 보자
- 주어진 문장 'She cooked pasta. It was delicous'라는 문장을 예로 들어보자.
tokens = [ [CLS], She, cooked, pasta, [SEP], It, was, delicous, [SEP] ]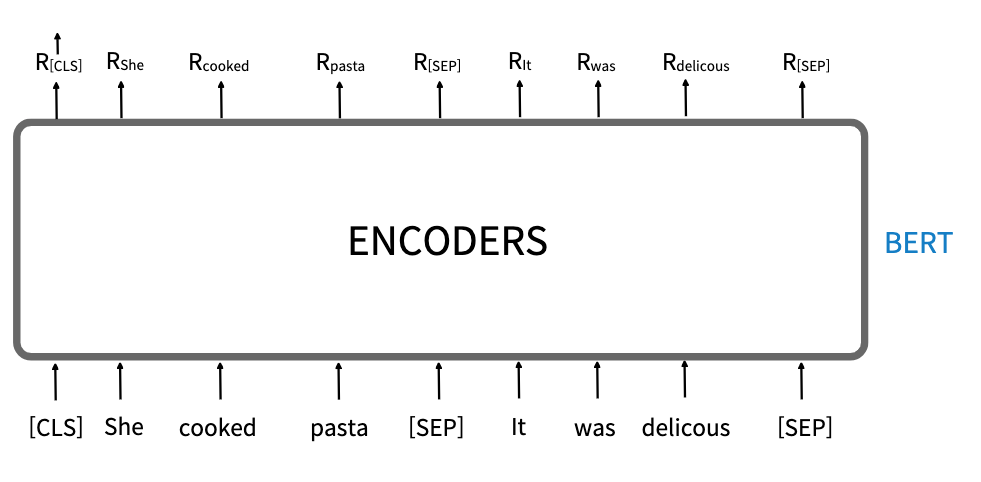
- 토큰화 한 데이터를 BERT에 입력을 하면 다음과 같이 표현 R을 반환한다.
- 그중 문장의 총체적인 표현을 가지고 있는 R[CLS] 를 문장의 표현으로 사용할 수 있따.
- 그러나 이 방식의 문제점은 특히 파인 튜닝 없이 사전 학습된 BERT 모델을 직접 사용하는 경우 [CLS] 토큰의 문장 표현이 정확하지 않다는 것이다.
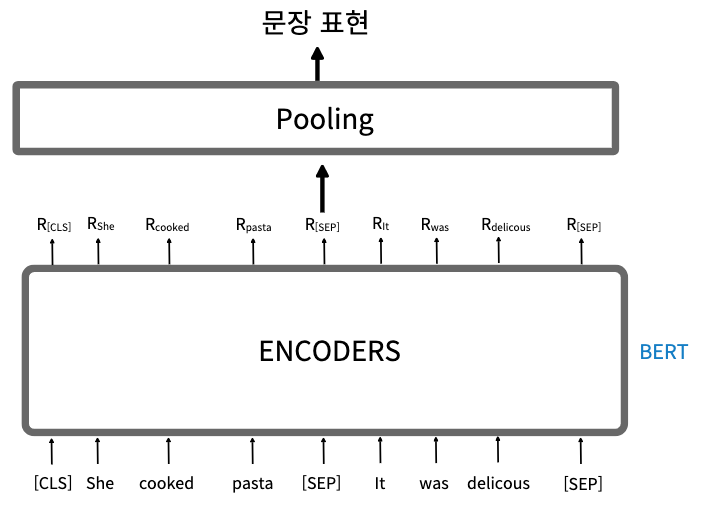
- 따라서 문장 표현으로 [CLS] 토큰을 사용하는 대신 Pooling을 사용할 수 있다.
1. 평균 풀링(mean pooling) : 모든 토큰의 표현에 평균 풀링으로 문장 표현을 얻으면 문장 표현은 본질적으로 모든 단어(토큰)의 의미를 가진다.
2. 최대 풀링(max pooling) : 모든 토큰의 표현에 최대 풀링으로 문장 표현을 얻으면 문장 표현은 본질적으로 중요한 단어의 의미를 갖는다.
1.2 sentence-BERT 이해하기
- SBERT는 사전 학습된 BERT 을 통해 문장 표현을 얻도록 파인 튜닝한다.
- 즉, SBERT는 기본적으로 문장 표현을 계산하기 위해 파인 튜닝된 사전 학습 BERT 모델이다.
- 여기서 SBERT의 특이한 점은 사전 학습된 BERT를 파인 튜닝하기 위해 sentence-BERT는 샴 및 트리플렛 네트워크 아키텍처를 사용하므로 더 빠르고, 정확한 문장 표현을 얻을 수 있다.
- SBERT는 문장 쌍을 입력하는 태스크로 샴 네터워크 아키텍쳐를 사용한다.
- 또는 트리플렛 손실 목적 함수를 가진 트리플렛 네트워크 아키텍처를 사용한다.
1) 문장 쌍 분류 태스크를 위한 sentence-BERT
- SBERT를 학습하는 첫 번째 방법은 문장 쌍 분류 태스크. 대표적으로는 NLI(Natural Language Inferencing) 문제를 푸는 것이다.
- NLI는 두 개의 문장이 주어지면 수반(entailment) 관계인지, 모순(contradiction 관계인지, 중립(neutral) 관계인지를 맞추는 문제이다.
-다음은 NLI 데이터의 예시이다.

- SBERT는 NLI 데이터를 학습하기 위해 다음과 같은 구조를 가진다.

- 샴 네트워크는 동일한 가중치를 공유하는 2개의 동일한 네트워크로 구성되어 있다.
- 따라서 여기서는 2개의 동일한 사전 학습된 BERT 모델들을 사용한다.
- 우선 문장 A와 문장 B 각각을 BERT의 입력으로 넣고, 앞서 BERT의 문장 임베딩을 얻기 위해 평균 풀링 또는 최대 풀링을 통해서 각가에 대한 문장 임베딩 벡터를 얻는다.
- 보통 sentence-BERT는 평균 풀링을 사용한다.
- 이렇게 구한 문장 임베딩 벡터를 이어주는 과정이 필요하다.
- 풀링을 통해 얻은 각각에 대한 문장 임베딩 벡터를 u v라고 했을때, u와 v, |u-v| 이 세가지 벡터를 연결한다.
$$ h = (u; v; | u - v | )$$
- ;은 연결 기호
- 만약 BERT의 문장 임베딩 벡터의 차원 n 이라면, 세 개의 벡터를 연결한 벡터 h의 차원은 3n이 됩니다.
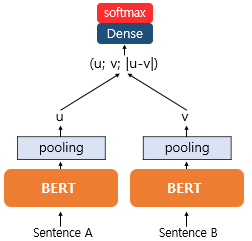
- 그리고 이 벡터를 출력층으로 보내 다중 클래스 분류 문제를 풀도록 한다.
- 다시 말해 분류하고자 하는 클래스의 개수가 k개 라면, 가중치 행렬 3n * k의 크기를 가지는 가중치 행렬 $W_y$을 곱한 후 softmax() 를 통과시킨다고 볼 수 있다.
$$ o = softmax(W_h^h$$
- 교차 엔트로피 손실(cross-entropy loss)을 최소화하도록 가중치(W)를 업데이트해 네트워크를 학습한다.
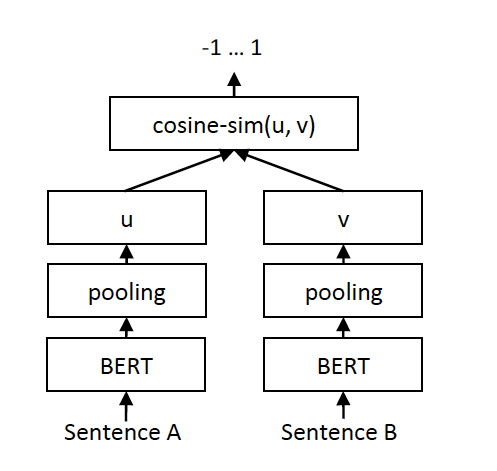
2) 문장 쌍 회귀 태스크를 위한 sentence-BERT
- 회귀 태스크의 목표는 주어진 두 문장 사이의 의미 유사도를 예측하는 것이다.
- 대표적으로 STS(Semantic Textual Similarity) 문제를 푸는 경우에 사용된다.
- STS란 두 개의 문장으로부터 의미적 유사성을 구하는 문제를 말한다.
- 두 문장의 임베딩 u v 사이의 코사인 유사도를 계산한다.
3) 트리플렛 네트워크 sentence-BERT
- 다음과 같이 기준 문장(anchor), 긍정 문장(positive), 부정 문장(negative)의 세 문장이 있다고 할때.
- 기준문과 긍정문 사이의 유사도가 기준문과 부정문 사이의 유사도보다 높게 하도록 학습시킨다.
다음과 같이 기준,긍정,부정 문장을 토큰화 및 풀링과정을 거쳐 각 문장의 표현을 얻는다.

- 긍,부,기 문장의 각 표현을 $S_p,S_n,S_a$라고 했을때,다음과 같은 트리플렛 목적 함수를 최소화 한다.
$$\max(margin + d(a, p) - d(a, n), 0)$$
|| || : 유클라디안 거리를 사용한 거리 메트릭을 의미한다.
d () : 두 샘플간의 거리
margin : $S_p$ 가 적어도 margin 만큼 $S_a$에 $S_n$ 보다 더 가깝다는 의미를 나타낸다. 본 논문에서는 1로 지정했다.
max(,0) : 값 중에서 최대 값을 구하는 함수. 본 수식에서는 이 차이의 결과가 양수면 loss를 계산, 음수면 0으로 두는 방식

1.2 sentence-BERT를 사용한 문장 표현 계산
pip install -U sentence-transformers- 먼저 sentence-transformers 라이브러리에서 SentenceTransformer 모듈을 가져온다.
from sentence_transformers import SentenceTransformer- 사전 학습된 sentence-BERT를 다운로드하고 로드한다.
model = SentenceTransformer('bert-base-nli-mean-tokens')- 온라인으로 제공되는 사전학습된 sentence-BERT 모델로는 다음과 같다.
1. bert-base-nli-cls-token
-> BERT-base를 가져와 NLI 데이터셋으로 파인튜닝했으며, [CLS] 토큰을 문장 표현으로 사용한다.
2. bert-base-nli-mean-token
-> BERT-base를 가져와 NLI 데이터셋으로 파인튜닝했으며, mean 풀링 전략을 사용한다.
3. roberta-base-nli-max-tokens
-> RoBERTa-base를 가져와 NLI 데이터셋으로 파인튜닝했으며, 최대 풀링 전략을 사용한다.
4. distilbert-base-nli-mean-token
-> DistillBERT-base를 가져와 NLI 데이터셋으로 파인튜닝했으며, 평균 풀링 전략을 사용한다.
- 샘플 문장을 정의하고, encode 함수로 사전 학습된 sentence-BERT를 이용해 문장 표현을 계산한다.
sentence = 'paris is a beautiful city'
sentence_representation = model.encode(sentence)- 문장 표현 크기(shape)를 출력해 본다.
print(sentence_representation.shape)
1.3 문장 유사도 계산하기
- 사전 학습된 sentence-bert를 사용해 두 문장 사이의 의미 유사도를 계산해보자.
- scipy와 sentence_transformers 라이브러리를 임포트한다.
import scipy
from sentence_transformers import SentenceTransformer, util사전 학습된 BERT 모델을 다운로드하고 로드한다.
model = SentenceTransformer('bert-base-nli-mean-tokens')- 유사도를 계산할 문장 쌍을 정의한다. 그리고 문장 쌍에서 각각의 문장 표현을 계산한다.
sentence1 = 'It was a great day'
sentence2 = 'Today was awesome'
sentence1_representation = model.encode(sentence1)
sentence2_representation = model.encode(sentence2)- 두 문장 표현 사이에서 코사인 유사도를 구한다.
cosine_sim = util.pytorch_cos_sim(sentence1_representation, sentence2_representation)
cosine_sim
'책 정리 > 구글 Bert의 정석' 카테고리의 다른 글
| BioBERT (0) | 2023.02.22 |
|---|---|
| 8-2 장. domain-BERT(ClinicalBERT) (0) | 2023.02.15 |
| 5장. 지식 증류 기반 BERT 파생 모델 (0) | 2023.02.08 |
| 4.4장-Span BERT (0) | 2023.02.01 |
| 4-3장. ELECTRA (1) | 2023.02.01 |



