domain-BERT
- 일반적인 위키피디아 corpus를 사용해 사전 학습 시킨 BERT를 사용하는 대신
- 특정 도메인 말뭉치에서 BERT를 처음부터 학습할 수도 있다.
- 이는 BERT가 특정 도메인 임베딩을 학습시키는 데 도움이 된다.
- domain BERT의 두가지 모델 ClinicalBERT, BioBERT에 대해 소개하고자 한다.
ClinicalBERT
- ClinicalBERT는 대규모 임상 말뭉치에서 사전 학습된 임상 domain-BERT 모델이다.
- 임상노트(clinical note), 진행 노트(progress note)는 환자에 대한 매우 유용한 정보를 포함한다.
- 임상 메모의 콘텍스트 표현을 이해하는 것은 자체 문법 구조, 약어 및 전문 용어와 관련되어 난이도가 높다.
- 따라서 임상 텍스트의 콘텍스트 표현을 이해하기 위해 많은 임상 문서로 ClinicalBERT를 사전 학습한다.
- ClinicalBERT에서 배운 표현은 많은 임상 통찰력, 임상 기록 요약, 질병과 치료 간의 관계 등을 이해하는 데 도움이 된다.
- 사전 학습이 끝난 ClinicalBERT는 재입원 예측, 체류 기간, 사망 위험 추정, 진단 예측 등과 같은 다양한 다운스트림 태스크에 사용된다.
ClinicalBERT 사전 학습
- ClinicalBERT는 MIMIC-III 임상 노트를 사용해 사전 학습된다.
MIMIC-III : 베스 이스라엘 디코니스 메디컬센터에서 제공하는 방대한 양의 건강과 관련된 데이터.
- ClinicalBERT는 BERT를 사전학습하는 것과 같이 MLM과 NSP 태스크를 이용해 사전 학습된다.

- 위 그림과 같이 마스킹된 단어가 있는 두 문장을 모델에 입력하고,
- 마스크된 단어와, 두 번째 문장이 첫번째 문장인지 다음 문장인지 여부를 예측하도록 모델을 학습한다.
ClinicalBERT 파인 튜닝 학습
- 사전 학습 후에는 재입원 예측, 입원 기간, 사망 위험 추정, 진단 예측 등 다양한 다운스트림 태스크에 맞춰 ClinicalBERT를 파인 튜닝할 수 있다.
- 다음과 같이 재입원을 예측하는 태스크를 위해 ClinicalBERT를 파인 튜닝한다고 가정하자.
- 우리의 목표는 30일 이내에 환자가 병원에 재 입원할 확률을 예측하는 것이다.

- 다음 그림과 같이 사전 학습된 ClinicalBERT에 임상 메모를 입력하고, 임상 메모의 표현을 반환한다.
- 그런 다음 [CLS] 토큰의 표현을 가져와 분류기(피드포워드 + 시그모이드) 에 입력하고, 확률을 반환한다.
- BERT에서 최대 토큰의 길이가 512라는 것은 누구나 알고 있는 사실이다.
- 만약 환자의 임상 기록이 512보다 더 많은 토큰으로 구성된 경우에는 어떻게 예측해야 할까?
- 이 경우 임상 노트(긴 시퀀스) 데이터를 여러 서브 시퀀스로 분할할 수 있다.
- 이제 각 서브 시퀀스 모델에 입력한 후 모든 서브 시퀀스를 개별적으로 예측한다.
- 위 식을 단계별로 이해해 보자.
(1)
- 서브 시퀀스가 있다고 가정해 보았을때, 재입원 예측과 관련된 유용한 정보가 모든 서브 시퀀스에 있지는 않다.
- 재입원 예측과 관련된 일부 서브 시퀀스가 있을 수 있으며, 재입원 예측과 관련 없는 일부 서브 시퀀스가 있을 수 있다.
- 따라서 모든 서브 시퀀스가 예측에 유용하지는 않으며 따라서 모든 서브 시퀀스에서 확률이 가장 높은 것만 사용하면 된다.

(2)
- 서브 시퀀스에 노이즈가 포함되어 있고, 노이즈로 최대 예측 확률을 얻는다고 가정했을때.
- 이런 경우 최종 예측으로 최대 확률을 선택하는 것은 잘못된 선택이다.
- 따라서 이를 방지하기 위해 모든 서브 시퀀스의 평균 확률도 포함된다.
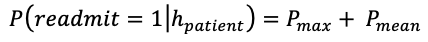
(3)
- 시퀀스 데이터의 길이가 길수록 서브시퀀스의 수(n)이 많아진다.
- 이 경우 노이즈로 인해 최대 확률을 최종 예측으로 선택할 가능성이 높아진다.
- 따라서 이 경우 평균 확률에 더 많은 중요성을 부여해야 한다.
- n에 의존하는 $P_mean$의 중요성을 더 주기 위해 스케일링 팩터리 C를 이용해 $\frac{n}{c}$를 곱한다.

(4)
- 다음으로 최종 점수를 정규화하기 위해 $1 + \frac{n}{c}$ 로 나누면 최종 식을 얻을 수 있다.

- 이러한 방식으로 사전 학습된 BERT를 활용하고 다운스트림 태스크에 맞게 파인 튜닝할 수 있다.

- 다음 표는 재입원 예측 다운스트림 태스크에 대한 여러 모델 간의 비교를 AUROC, AUPRC, RP80로 비교한 표이다.
AUROC (Area Under the Receiver Operating Characteristic Curve) 는 분류 모델의 성능을 평가하는 방법으로, 얼마나 잘 실제 positive 샘플과 negative 샘플을 구분하는지를 나타낸 값입니다.
AUPRC (Area Under the Precision-Recall Curve) 는 분류 모델의 정밀도와 재현율 사이의 관계를 나타내는 값입니다. 정밀도와 재현율 사이의 trade-off를 보여주고, 분류 모델이 얼마나 잘 positive 샘플을 잡는지에 대한 평가를 합니다.
RP80 (Recall at 80% Precision) 는 분류 모델의 정밀도가 80%일 때의 재현율을 나타내는 값입니다. 정밀도가 80%일 때, 얼마나 많은 positive 샘플이 정확하게 잡혔는지를 나타냅니다.
- 다음은 의학 용어의 표현들을 계산한 후 t-SNE를 이용해 각 용어들의 표현들을 도표화 한 것이다.

- 다음 그림을 통해 신체기관이 서로 연관된 용어끼리 가까이 있는 것을 볼 수 있다.
- 왼쪽 위에서부터 오른쪽 위방향으로 담관암, 울혈성 심부전 폐색전증, 심장, 심근 경색
'책 정리 > 구글 Bert의 정석' 카테고리의 다른 글
| BioBERT (0) | 2023.02.22 |
|---|---|
| 8-1 장. sentence-BERT (0) | 2023.02.14 |
| 5장. 지식 증류 기반 BERT 파생 모델 (0) | 2023.02.08 |
| 4.4장-Span BERT (0) | 2023.02.01 |
| 4-3장. ELECTRA (1) | 2023.02.01 |



