1. 사전 학습된 BERT 모델 탐색
- 2장에서 MLM과 NSP를 사용하여 BERT를 사전학습시키는 방법을 배웠다.
- 그러나 BERT를 처음부터 사전 학습시키는 것은 계산 비용이 많이 든다.
- 따라서 사전 학습된 공개 BERT 모델을 다운로드해 사용하는게 효과적이다.
- 구글은 사전학습된 BERT 모델을 오픈소스로 제공했으며 구글 리서치의 깃허브 저장소(https://github.com/google-research/bert.git)에서 다운로드할 수 있다.

- 사전 학습된 모델은 BERT-uncased 및 BERT-cased 형식으로도 제공된다.
BERT-uncased
1. 입력 단어를 소문자로 만들어준다.
2. 어떠한 accent marks를 없애준다.
MyDrive -> mydrive
français -> francais
BERT-cased
1. 입력단어에 대해 어떠한 변환도 이루어지지 않는다.
MyDrive -> MyDrive
français -> français
- BERT-cased의 경우 NER과 같은 특정 작업을 수행하는 경우 사용된다.
*NER
Named Entity Recognition (개체명 인식)
- NER은 미리 정의해 둔 사람, 회사, 장소, 단위 등에 해당하는 단어(개체명)를 문서에서 인식하여 추출 분류하는 기법이다.
- 추출된 개체명은 인명(person), 지명(location), 기관명(organization), 시간(time) 등으로 분류된다.
- 개체명 인식은 정보 추출을 목적으로 시작되어 NLP, 정보 검색 등에 사용된다.
- 이를 제외한 대부분은 BERT-uncased를 사용하는것이 더 좋다.
- 이러한 사전 학습 모델은 정확히 어떤 방식으로 활용할 수 있을까? 다음과 같이 두 가지 방법으로 사용할 수 있다.
- 임베딩을 추출해 특정 추출기로 사용
- 사전 학습된 BERT 모델을 텍스트 분류, 질문-응답 등과 같은 Downstream Task에 맞게 Fine-Tuning 한다.
2. 사전 학습된 BERT에서 임베딩을 추출하는 방법
- 다음과 같은 문장이 있다고 가정한다.
I love Paris(나는 파리를 사랑한다.)
- 문장에서 각 단어의 문맥 임베딩을 추출해야 한다면 다음과 같은 과정을 따른다.
- 문장을 토큰화
- 사전 학습된 BERT에 토큰을 입력
- 각 토큰에 대한 임베딩 반환
- 토큰(단어) 수준 표현을 얻는 것 외에도 문장 수준의 표현을 얻을 수도 있다.
| 문장 | 레이블 |
| l love paris | 1 |
| Sam hated the movie | 0 |
| ... | .... |
| We loved the game | 1 |
- 위 표는 긍정적인 문장에는 1을, 부정적인 문장에는 0을 labeling한 감정 분류 Task를 학습시키기 위한 데이터 셋이다.
- 그러나 주어진 데이터셋은 텍스트이므로 문장을 벡터화 하는 방법을 알아보겠다.
문장 벡터화
1. 먼저 Wordpiece Embedding 방식을 적용하여 문장을 토큰화한다.
tokens = [I,love,paris]
2. 토큰 시작부분에 [CLS], 문장의 끝에 [SEP] 토큰을 추가
tokens = [[CLS],I,love,paris,[SEP]]
- 각 문장의 길이가 다양하듯이, 토큰의 길이도 다양하다.
- 따라서 모든 토큰의 길이를 동일하게 유지해야 한다.
- 위 토큰의 길이는 5다. 만약 토큰의 길이를 7로 통일한다고 가정한다면, [PAD]토큰을 추가하여 길이를 맞춰준다.
tokens = [[CLS],I,love,paris,[SEP],[PAD],[PAD]]
3. [PAD]토큰이 실제 토큰의 일부가 아니라는것을 모델에게 이해시키기
- BERT를 학습할 때 불필요하게 [PAD] 토큰에 대해 어텐션을 하지 않도록 구분시켜주어야 함.
- 이를 위해 실제 토큰이 있는 위치에는 마스크 값을 1로 설정, [PAD]토큰이 있는 위치에는 0을 설정한다.
attention_mask = [1,1,1,1,1,0,0]

4. 실제 토큰에 고유한 토큰ID로 매핑한다.
token_ids = [101, 1045, 2293, 3000, 102, 0, 0]
5. 사전 학습된 BERT에 Attention Mask, token_ids를 공급하고 각 토큰의 벡터 표현을 얻는다.

- 위 그림에서 볼 수 있듯이 문맥화된 단어 임베딩을 얻을 수 있다.
- $R_{she}, R_{[SEP]}$와 같은 토큰은 각 단어에 대한 표현을 의미한다.
- 반면 $R_{[CLS]}$는 문장의
2.1 사전 학습된 BERT에서 임베딩을 추출하기 (실습)
Hugging Face
- Hugging Face 웹사이트에서 데이터와 사전학습 모델을 다운로드 받아 딥러닝 모델의 개발 생산성을 높일 수 있다.
- Hugging Face에서 제공하는 BERT 모델은 12개의 인코더가 있는 모델이며, 모두 소문자로 변환한 uncased 토큰으로 학습되었다.
- 라이브러리에는 100개 이상의 언어로 학습된 수천 개의 모델이 포함되어 있다.
- 트랜스포머 라이브러리의 많은 장점 중 하나는 파이토치 및 텐서플로와 모두 호환된다는 것이다.
- 먼저 트랜스포머를 설치해주자.
%pip install transformers- 그리고 임베딩에 필요한 라이브러리들을 가져와준다.
from transformers import BertModel, BertTokenizer
import torch- 아래 코드로 bert-base-uncased 모델을 다운로드한다. (다운로드 활성화가 뜨면 확인 눌러주면 됨.)
model = BertModel.from_pretrained('bert-base-uncased')- 다음으로 bert-base-uncased 모델을 사전 학습시키는데 사용된 토크나이저를 다운로드한다.
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
입력 전처리하기
- 문장을 아래와 같이 정의한다.
sentence = 'I love Paris'- 문장을 토큰화하고 토큰을 얻는다.
token = tokenizer.tokenize(sentence)
print(token)
- 시작부분에 [CLS] 토큰을, 문장 끝에 [SEP] 토큰을 추가한다.
token = ['[CLS]'] + token + ['[SEP]']
print(token)
- 토큰 목록의 길이를 7로 유지해야 한다고 가정한다면 나머지 2자리에 [PAD]토큰을 추가해야 한다.
token = token + ['[PAD]'] + ['[PAD]']
token
- 이 토큰을 기반으로 Attention Mask를 만든다.
attention_mask = [1 if i!='[PAD]' else 0 for i in token]
attention_mask
- 모든 토큰을 다음과 같이 토큰 ID로 변환한다.
token_ids = tokenizer.convert_tokens_to_ids(token)
token_ids
- 이제 token_ids, attention_mask를 다음 코드와 같이 텐서로 변환한다.
token_ids = torch.tensor(token_ids).unsqueeze(0)
attention_mask = torch.tensor(attention_mask).unsqueeze(0)
임베딩 추출하기
- token_ids, attention_mask를 모델에 입력하고 임베딩을 획득한다.
- 모델은 두 값으로 구성된 튜플로 출력을 반환한다.
- 은닉 상태 표현(hidden_rep) : 최종 인코더에서 얻은 모든 표현 벡터로 구성됨
- cls_head : [CLS] 토큰의 표현으로 구성된다.
hidden_rep, cls_head = model(token_ids, attention_mask = attention_mask)
print(hidden_rep.shape)- 위 출력문은 다음과 같이 출력된다.
torch.size([1,7,768])
- [1,7,768]은 [batch_size, sequence_length(단어길이), hidden_size(표현벡터의 크기)]를 의미한다.
- 다음과 같이 각 토큰의 표현을 얻을 수 있다.
> hidden_rep[0][0]은 첫번째 토큰인 [CLS]의 표현 벡터를 제공한다.
> hidden_rep[0][1]은 두번째 토큰인 I의 표현 벡터를 제공한다.
> hidden_rep[0][2]은 세번째 토큰인 love의 표현 벡터를 제공한다.
- 이러한 방식으로 모든 토큰의 문맥별 표현 벡터를 얻을 수 있다. (이는 기본적으로 주어진 문장에 있는 모든 단어의 문맥화된 단어 임베딩)
print(hidden_rep.shape)- cls_head에는 [CLS]토큰의 표현이 포함된다.
- [CLS] 토큰의 표현이 문장 전체의 표현을 보유하고 있다. 즉, I love Paris 문장의 표현벡터로 사용할 수 있다.
2.2 BERT의 모든 인코더 레이어에서 임베딩을 추출하는 방법.
- BERT는 항상 최종 인코더에서만 얻은 임베딩만 고려해야 하는것은 아니다.
- 다른 인코더 레이어에서 임베딩을 추출할 수도 있다.
from transformers import BertModel, BertTokenizer
import torch
model = BertModel.from_pretrained('bert-base-uncased', output_hidden_states = True)
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')- 먼저 필요한 라이브러리와 사전 학습된 BERT및 토크나이저를 다운로드한다.
- 사전학습된 BERT 모델을 다운로드 할때 output_hidden_states를 True로 지정해 주는 것은 모든 인코더 레이어에서 임베딩을 얻기 위함이다.
- 이제 입력 문장을 전처리해보자.
sentence = 'I love Paris'
token = tokenizer.tokenize(sentence)
print(token)
token = ['[CLS]'] + token + ['[SEP]']
token = token + ['[PAD]'] + ['[PAD]']
attention_mask = [1 if i!='[PAD]' else 0 for i in token]
token_ids = tokenizer.convert_tokens_to_ids(token)
token_ids = torch.tensor(token_ids).unsqueeze(0)
attention_mask = torch.tensor(attention_mask).unsqueeze(0)
print(token_ids)
print(attention_mask)
- 이제 입력 데이터를 모델이 넣어 임베딩을 출력해보자
- output_hidden_states를 True로 지정해 주었기 때문에 모델은 다음과 같이 3가지 값이 있는 튜플을 반환한다.
(last_hidden_state,pooler_output,hidden_states) = model(token_ids, attention_mask = attention_mask)last_hidden_state : 최종 인코더 계층에사만 얻은 모든 토큰의 표현을 가짐
pooler_output : 최종 인코더 계층의[CLS] 토큰 표현을 나타내며, 선형 및 tanh 함수에 의해 계산된다.
hidden_states : 모든 인코더 계층에서 얻은 모든 토큰의 표현을 포함한다.
3. 다운스트림 태스크를 위한 BERT 파인 튜닝 방법
- Fine-Tuning은 Pre-training된 모델을 Downstream-Task에 맞게 가중치를 업데이트하는 과정을 의미한다.
- BERT의 Downstream-Task 유형은 대략 4가지다
- 텍스트 분류
- 자연어 추론(NEI)
- 개체명 인식(NER)
- 질문-응답
* BERT 모델을 특징 추출기로 사용한것과 파인튜닝하는 것에 대한 차이점.
- 두 방법 모두 BERT에서 표현 임베딩을 추출 후 임베딩을 분류기에 입력하고 분류기를 학습하여 분류를 수행한다.
BERT 모델을 특징 추출기로 사용한것 (2.1장)
- 하지만 이 방식의 경우 사전 학습된 BERT 모델이 아닌 분류기의 가중치만 업데이트된다.
BERT 모델을 파인 튜닝 한것.
- 이 방식은 분류기 뿐만 아니라 BERT 모델의 가중치도 함께 업데이트 된다.
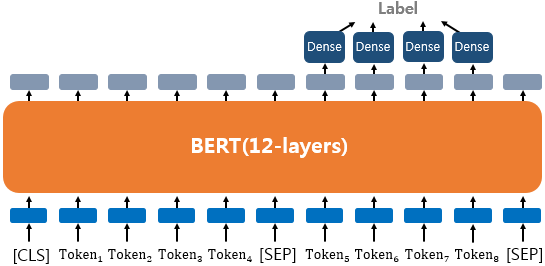
3.1 텍스트 분류
- 이 유형은 영화 리뷰 감정 분류, 로이터 뉴스 분류 등과 같이 입력된 문서에 대해서 분류를 하는 유형이다.
- 텍스트 분류 태스크는 BERT를 거쳐 나온 다른 모든 토큰의 표현은 무시하고 [CLS] 토큰에 대한 표현 임베딩만 사용한다.
- $R_{[CLS]}$를 분류기(소프트맥스 함수가 있는 피드포워드 네트워크)에 입력하고 학습시켜 감정을 분류한다.

IMDB 데이터셋을 기반으로 한 감정분석 태스크
- IMDB 데이터셋은 영화 리뷰 텍스트와 리뷰의 감정 레이블로 구성된다.
- 먼저 필요한 라이브러리, 모델, 데이터셋 등을 불러와준다.
* IMDB 데이터셋 설치
!gdown https://drive.google.com/uc?id=11_M4ootuT7I1G0RlihcC0cA3Elqotlc-from transformers import BertForSequenceClassification, BertTokenizerFast, Trainer, TrainingArguments
from nlp import load_dataset
import torch
import numpy as np
# IMDB 데이터셋 로드
dataset = load_dataset('csv', data_files='./imdbs.csv', split='train')
# 학습 및 테스트셋으로 분할
dataset = dataset.train_test_split(test_size=0.3)
# 학습 및 테스트 셋 만들기
train_set = dataset['train']
test_set = dataset['test']
# 모델 불러오기
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
# 토크나이저 인스턴스 생성
tokenizer = BertTokenizerFast.from_pretrained('bert-base-uncased')
- 이제 불러온 데이터 셋을 토큰화해주도록 하자
tokenizer('I love Paris')#위 코드는 다음을 반환한다.
{'input_ids': [101, 1045, 2293, 3000, 102], 'token_type_ids': [0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1]}
- 토크나이저를 사용하면 여러 문장을 전달하고 자동으로 패딩을 수행할 수도 있다.
tokenizer(['I love Paris', 'birds fly','snow fall'], padding = True, max_length=5){'input_ids': [[101, 1045, 2293, 3000, 102], [101, 5055, 4875, 102, 0], [101, 4586, 2991, 102, 0]], 'token_type_ids': [[0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0]], 'attention_mask': [[1, 1, 1, 1, 1], [1, 1, 1, 1, 0], [1, 1, 1, 1, 0]]}
- 따라서 다음과 같이 데이터셋을 처리하는 preprocess라는 함수를 정의해보자.
def preprocess(data):
return tokenizer(data['text'], padding=True, truncation=True)- 정의한 함수를 통해 데이터셋을 전처리한다.
train_set = train_set.map(preprocess, batched=True, batch_size=len(train_set))
test_set = test_set.map(preprocess, batched=True, batch_size=len(test_set))*AttributeError: module 'dill._dill' has no attribute 'log'
log라 속성은 최신 버전에서 제거되었으므로
log속성을 사용하기 위해선 이전 버전으로 업데이트해주면 된다.
pip install dill==0.3.5.1.https://stackoverflow.com/questions/74857932/attributeerror-module-dill-dill-has-no-attribute-log
- 다음으로 set_format함수를 사용해 다음 코드와 같이 데이터셋이 필요한 열과 필요한 형식을 입력한다.
train_set.set_format('torch', columns=['input_ids', 'attention_mask', 'label'])
test_set.set_format('torch', columns=['input_ids', 'attention_mask', 'label'])- 이제 데이터셋이 준비되었으니 모델을 학습해보자
# 배치사이즈 및 에포크 정의
batch_size = 8
epochs = 2
# 웜업 스텝 크기 및 weight decay 정의
warmup_steps = 500
weight_decay = 0.01* weight decay?
Overfitting을 막는 학습 기법의 하나.
모델이 train 데이터에 대해 너무 완벽하게 맞춰짐으로써 오차가 0이 되었을때, 이를 Overfit되었다고 말한다.
Overfit은 모델이 상당히 복잡하게 구성되어있는데, 학습데이터를 표현하는 정보가 적을때 즉 학습 데이터가 단순할 때 발생한다.
데이터가 단순하고 모델이 복잡하면, 학습을 하면서 굉장히 작은 값이었던 weight들의 값이 점점 증가하게 되면서 Overfitting이 발생하게 된다.
weight 값이 커지게 될수록 학습 데이터에 영향을 많이 받게 되고, 학습 데이터에 딱 모델이 맞춰지게 된다.
이를 'local noise 의 영향을 크게 받아서, outlier들에 모델이 맞춰지는 현상'이라고 표현한다.
이러한 문제를 개선하기 위해 weight decay 기법을 제안한다.
weight decay는 weight들의 값이 증가하는 것을 제한함으로써, 모델의 복잡도를 감소시킴으로써 제한하는 기법이다.
즉, weight를 조금씩 감소시켜서 overfitting을 방지한다.
- 다음으로 학습 인수와 트레이너를 정의한다.
# 학습 인수 정의
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=epochs,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
warmup_steps=warmup_steps,
weight_decay=weight_decay,
logging_dir='./logs',
)
# 트레이너 정의
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_set,
eval_dataset=test_set
)- 이제 학습
trainer.train()
trainer.evaluate()
3.2 자연어추론(natural language inference) NLI
- NLI에서 모델은 가정이 주어진 전제에 참인지 거짓인지 중립인지 여부를 결정하는 태스크이다.
- 해결 가능한 문제
- 같은 text내 속하는지, 연결되는지, 같은 주제인지 파악
- 답변 생성, 언어간 자연어 추론

- 자연어 추론 문제란, 두 문장이 주어졌을 때, 하나의 문장이 다른 문장과 논리적으로 어떤 관계에 있는지를 분류함.
- 유형으로는 모순관계(contradiction), 함의관계(entailment), 중립관계(neutral)가 있다.
3.2 질의 응답
- 질의 응답 태스크(question-answering task)에서는 질문에 대한 응답이 포함된 단락과 함께 질문이 제공된다.
- 이 태스크의 목표는 주어진 질문에 대한 단락에서 답을 추출하는 것이다.
- 입력값으로 질문과 본문을 받고, 본문의 일부분을 추출하여 질문에 답변하는 것이다.
질문
: 강우가 떨어지도록 영향을 주는 것은?
본문
: 기상학에서 강우는 대기 수증기가 응결되어 중력의 영향을 받고 떨어지는 것을 의미합니다. 강우의 주요 형태는 이슬비, 비, 진눈깨비, 눈, 싸락눈 및 우박이 있습니다.
정답
: 중력
- 그렇다면 어떻게 BERT를 Fine-Tuning 해야 할까??
1. 주어진 단락의 답을 포함하는 text 범위의 시작과 끝의 인덱시를 이해해야 한다.
2. 답을 포함하는 인덱스를 찾기 위해 단락 내 답의 시작과 끝 토큰이 될 확률을 각각 구한다.
시작 벡터 S, 끝 벡터 E의 값을 학습한다.
- 먼저 본문 내 각 단어의 응답의 시작 토큰이 될 확률 P를 계한해 보자
- $R_i$ : 각 토큰 i 에 대한 토큰 표현 벡터
- S : 시작 벡터
- E : 끝 벡터
- S·$R_i$ : 내적 계산

시작 token이 될 확률이 높은 token의 index를 선택해 시작 index를 구한다
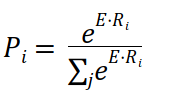
끝 token이 될 확률이 높은 token의 index를 선택해 끝 index를 구한다.
- 이제 질문-단락 쌍을 토큰화하고, 토큰을 사전 학습된 BERT 모델에 입력해 모든 토큰의 임베딩을 반환한다.
- 임베딩을 계산한 후 시작/끝 벡터로 내적을 계산한 뒤 softmax함수를 적용한다.
- 단락의 각 토큰에 대해서 시작/끝 단어일 확률을 얻는다.
질의응답 Task 수행하기
- 먼저 필요 라이브러리를 설치해 준다.
import torch
from transformers import BertForQuestionAnswering, BertTokenizer- 이제 모델을 다운로드 및 로드한다.
- 현재 다운스트림 태스크를 수행하기 위해 SQUAD 데이터셋을 기반으로 파인 튜닝된 모델을 사용할 것이다.
model = BertForQuestionAnswering.from_pretrained('bert-large-uncased-whole-word-masking-finetuned-squad')
tokenizer = BertTokenizer.from_pretrained('bert-large-uncased-whole-word-masking-finetuned-squad')
- 먼저 질문 및 단락 텍스트를 사용해 BERT의 입력을 정의한다.
question = "What is the immune system?"
paragraph = "The immune system is a system of many biological structures and processes within an organism that protects against disease. To function properly, an immune system must detect a wide variety of agents, known as pathogens, from viruses to parasitic worms, and distinguish them from the organism's own healthy tissue."- 질문 시작 부분에 [CLS]토큰을, 질문가 단락 끝에 [SEP] 토큰을 추가한다.
- 그리고 토큰화한다.
question = '[CLS] ' + question + '[SEP]'
paragraph = paragraph + '[SEP]'
# 토큰화
question_tokens = tokenizer.tokenize(question)
paragraph_tokens = tokenizer.tokenize(paragraph)- 질문 및 단락 토큰을 결합해 input_ids로 변환한다.
tokens = question_tokens + paragraph_tokens
input_ids = tokenizer.convert_tokens_to_ids(tokens)- 다음으로 세그먼트 아이디를 정의한다.
- 세그먼트 아이디는 질문의 모든 토큰에 0을, 단락의 모든 토큰에 1을 부여한다.
segment_ids = [0] * len(question_tokens)
segment_ids += [1] * len(paragraph_tokens)- 텐서로 변환
input_ids = torch.tensor([input_ids])
segment_ids = torch.tensor([segment_ids])- 이제 모든 토큰에 대한 시작 점수와 끝 점수를 반환하는 모델에 input_ids및 segment_ids를 입력한다.
- 이 scores 변수에는 start_logits(시작 점수)와, end_logits(끝 점수)에 대한 텐서를 담고 있다.
scores = model(input_ids, token_type_ids = segment_ids)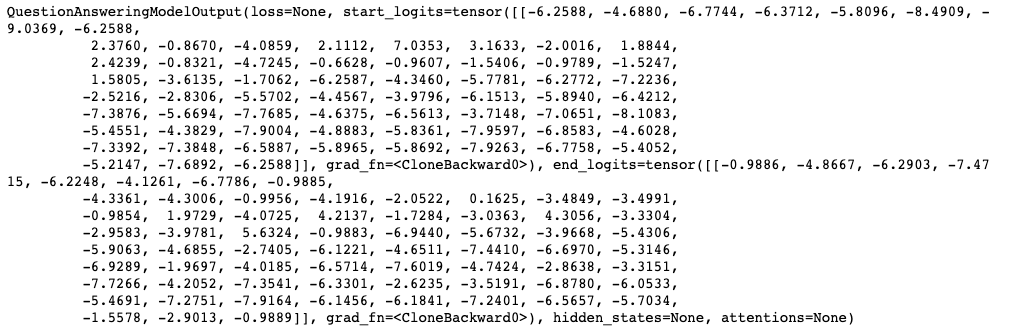
- argmax()를 통해 시작과 끝 텍스트의 인덱스를 구한다.
start_index = torch.argmax(scores.start_logits)
end_index = torch.argmax(scores.end_logits)- 이제 정답 문장을 출력한다.
print(' '.join(tokens[start_index:end_index+1]))output: a system of many biological structures and processes within an organism that protects against disease
3.2 개체명 인식(named entity recognition) NER
- NER에서 목표는 개체명을 미리 정의된 범주로 분류하는 것이다.
- 예를들어 "유정이는 2018년에 골드만삭스에 입사했다." 라는 문장이 있을 때, 사람(person), 조직(organization), 시간(time)에 대해 개체명 인식을 수행하는 모델이라면 다음과 같은 결과를 보여준다.
유정-사람
2018년-시간
골드만삭스-조직
'책 정리 > 구글 Bert의 정석' 카테고리의 다른 글
| 5장. 지식 증류 기반 BERT 파생 모델 (0) | 2023.02.08 |
|---|---|
| 4.4장-Span BERT (0) | 2023.02.01 |
| 4-3장. ELECTRA (1) | 2023.02.01 |
| 2장. BERT 시작하기 (0) | 2023.01.29 |
| 1 . 트랜스 포머 (1) | 2023.01.02 |



