head()
-head는 default 값으로 앞에서부터 5개의 행이 조회 된다.
-파라미터로 숫자를 넣어 조회하고 싶은 행의 갯수를 지정할 수 있다.
df.head()
df.head(3)
tail()
-tail은 반대로 default 값으로 뒤에서부터 5개의 행이 조회 된다.
-파라미터로 숫자를 넣어 조회하고 싶은 행의 갯수를지정할 수 있다.
df.tail()
df.tail(3)
info()
-열(column)별 정보를 보여준다.
df.info()
RangeIndex: 891 entries --> 891개의 행을 가진 데이터프레임을 의미.
Non-Null Count --> 각 columns 별 결측치 데이터를 가지고 있지 않은 수.
*deck열의 경우 891-203, 총 681개의 데이터가 결측치 데이터로 이루어져 있다.
Dtype: 데이터 타입
describe()
-각 columns에 대한 요약 통계를 제공함.
-수치형 column(numerical column)의 통계를 기본으로 보여준다.
df.describe()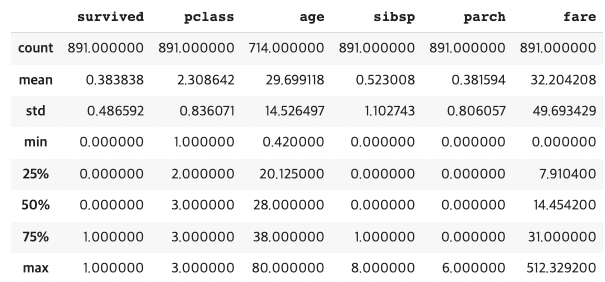
*categorical column(문자열 컬럼)의 통계는 나오지 않았지만 include='object'를 입력하여 문자열 컬럼에 대한 요약 통계를 확인해 볼 수 있다.
df.describe(include='object')
unique: 몇개의 문자열로 분류되어 있는지(sex의 경우 man, male 두개의 카테고리로 분류되어 있으므로 2)
top: 가장 많이 출현한 카테고리는 무엇인지.
freq: 가장 많이 출현한 카테고리는 몇번 출현했는지.
value_counts() 중요!
-column 별 값의 분포를 확인할 때 사용
df['who'].value_counts()
*who 라는 컬럼에 man은 537회, woman은 271회, child는 83회 출현하였다.
속성들
*속성 값은 함수형으로 조회하지 않는다.
#X
df.ndim()
#O
df.ndim1.ndim
-차원을 나타낸다. DataFrame의 경우 2가 출력된다

2.shape
-(행,열)순서로 출력된다.

3.index
-기본 설정된 RangeIndex가 출력된다.

4.columns
-열을 출력한다.

5.values
-데이터 값들을 출력한다.(안쪽에 있는 데이터)

6.T
-전치, 행과 열 바꾸기

DataFrame에 사용되는 함수 및 속성들을 한번에 여러개씩 사용할 수 있다.
-이를 체이닝이라고 한다.
df.describe().T.head()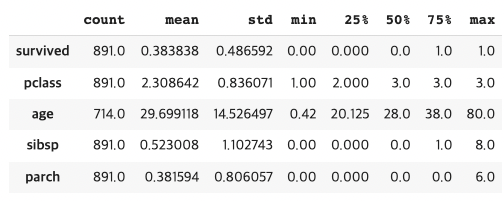
타입 변환
-astype()을 사용하여 원하는 데이터 타입으로 변환한다.
df['pclass'].astype('int32').head()
#dtype object로 변경
df['pclass'].astype('str').head()
#dtype category로 변경
df['pclass'].astype('category').head()
*category로 변경시 카테고리들이 같이 출력된다.
정렬
sort_index(index 정렬)
-index 기준으로 정렬함
df.sort_index().head(5)
*내림차순으로 정렬하려면, ascending=False 옵션 값으로 설정한다.
df.sort_index(ascending=False).head(5)
sort_values(값에 대한 정렬)
-값을 기준으로 행을 정렬함.
-by에 기준이 되는 행을 설정한다.
df.sort_values(by='age').head()
-오름차순/내림차순을 컬럼 별로 지정할 수있다.(내림차순의 경우 ascending=False)
df.sort_values(by='age', ascending=False).head()
-문자열 컬럼도 오름/내림차순 정렬이 된다 이의 경우 알파벳 순으로 정렬된다.
df.sort_values(by='class', ascending=False).head()
df.sort_values(by=['fare', 'age']).head()
*먼저 fare 기준으로 정렬하고, fare 컬럼에서 동률이 발생했을 경우 age를 기준으로 정렬한다.
-오름/내림차순 정렬도 컬럼 각각에 지정해 줄 수 있다.
df.sort_values(by=['fare', 'age'], ascending=[False, True]).head()
*fare을 오름 차순으로 정렬한 후 fare컬럼에서 동률이 발생할 경우 age를 내림차순을 기준으로 정렬하도록 한다.
IOC
-Ioc는 함수가 아닌 인덱서 이므로 괄호() 가아닌 대괄호[] 를 사용해 주어야 한다.
df.loc[5, 'class']*[행, 열]을 넣어 주면 하나의 단일 데이터를 가져온다.

fancy indexing
df.loc[2:5,['age','fare','who']]*2번 행에서 5번 행까지 age, fare, who 컬럼을 가져 온다.
indexing
df.loc[2:5, 'class':'deck'].head()*2번행에서 5번 행까지 class~deck 컬럼을 가져오겠다.

*슬라이싱 방법은 파이썬의 배열 슬라이싱 방법과 동일하다.
loc - 조건 필터
-boolean index를 만들어 조건에 맞는 데이터만 추출해 낼 수 있다.
condition = (df['who'] == 'man')
condition.head()*who 컬럼에 man인 데이터가 True인 Series를 condition 변수에 넣어줌.

#case1
df[condition].head()
#case2
df.loc[condition].head()
*Series 내에서 true인 행만 필터링 되어 출력됨.
-조건에 맞는 데이터를 추출하는 방식은 총 두가지 방식이 존재한다. 둘다 똑같은 결과를 출력하지만
-다만 loc를 사용하는것을 추천한다.(값을 대입했을때 이슈 발생)

*값을 대입하여 변경했음에도 불구하고 값이 변경되지 않았다는 문구가 뜬다.
#두가지 방식 모두 동일한 결과를 출력한다.
df.loc[condition].['age']=10
df.loc[condition, 'age'] = 10
df[condition].head()
loc - 다중 조건
-다중 조건은 먼저 각각의 boolean series를 형성하고 and/or연산자로 복합 조건을 생성한다.(and는 &, or은 |)
# 조건1 정의
condition1 = (df['fare'] > 30)
# 조건2 정의
condition2 = (df['who'] == 'woman')df.loc[condition1 & condition2].head()
df.loc[condition1 | condition2].head()
원하는 컬럼의 평균값을 구해오고 싶을땐
.mean을 사용한다.
df['age'].mean()iloc
-loc와 유사하지만, Index만 허용한다.(반드시 숫자로만 인덱싱이 가능하다.)
-loc와 마찬가지고, indexting/slicing 모두 가능하다.

fancy indexing
-[행(숫자로만)],[열(숫자로만)]]
df.iloc[[0, 3, 4], [0, 1, 5, 6]]
-슬라이싱의 경우 loc는 뒷 인덱스까지 포함시켜줬지만, iloc의 경우 뒷 인덱스까지 포함시키지 않는다.
df.iloc[:3, :5]
at과 iat
-각각 loc와 iloc를 대체해 주는 기능이다. loc,iloc보다 속도가 빠르다는 장점이 있지만, 실질적인 효용성은 떨어진다.
df.at[0, 'fare']df.iat[0, 5]
where
-pandas의 where는 Numpy의 where와 동작이 다르다.

-
- cond:조건문
- other:조건을 만족하지 못하는 요소에 할당할 값
df['fare'].where(df['fare'] < 20, 0).tail(10)-fare 컬럼에서 20을 넘는 데이터는 0으로 지정해 주어라.

전체 DataFrame에 적용시 다음과 같이 조건이 해당하는 값 외에는 모두 NaN 값으로 채워지게 된다.
df.where(df['fare'] < 10).head()
isin
-특정 값의 포함 여부는 isin 함수를 통해 비교가 가능하다(파이썬의 in 키워드는 사용이 불가능 하다.)
sample = pd.DataFrame({'name': ['kim', 'lee', 'park', 'choi'],
'age': [24, 27, 34, 19]
})sample['name'].isin(['kim', 'lee'])
sample.isin(['kim', 'lee'])
*컬럼명을 지정해 주지 않는다면 전체 컬럼에 해당 키워드가 존재하는지 확인하게 된다.
-loc를 활용한 조건 필터링 으로도 찰떡 궁합이다.
condition = sample['name'].isin(['kim', 'lee'])sample.loc[condition]
sample.loc[sample['name'].isin(['kim','lee'])]
'Data-Analysis > Pandas' 카테고리의 다른 글
| Pandas(Excel, CSV 파일 불러오기) (1) | 2022.10.11 |
|---|---|
| Pandas(DataFrame) (0) | 2022.10.11 |
| Pandas(Series, Indexing) (0) | 2022.10.11 |


