pandas를 통해 엑셀 파일을 불러올 수 있다.
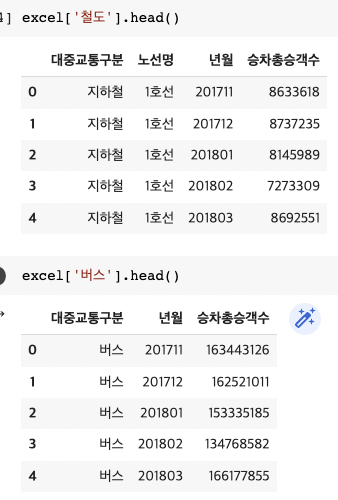
excel = pd.read_excel('data/seoul_transportation.xlsx', sheet_name='철도', engine='openpyxl')*sheet_name : 불러올 sheet이름

exce문서 왼쪽 하단에 위치해 있다.
[참고] pd.read_excel()로 엑셀 데이터 로드시 에러 발생한다면 engine='openpyxl'을 추가
excel.head()*.head(): 데이터의 처음부터 5번째 줄까지만 표시해줌.
하나의 sheet말고 모든 sheet를 다 가져 오고 싶다면 sheet_name=None으로 지정해주면 된다.
가지고 올때는 Dictionary 형태로 가지고 오며, keys()로 시트명을 조회할 수 있다.
excel = pd.read_excel('data/seoul_transportation.xlsx', sheet_name=None, engine='openpyxl')
excel
excel.keys()*.keys()를 통해 포함하고 있는 시트를 조회할 수 있다.

Excel 저장하기
-DataFrame을 Excel로 저장할 수 있으며, Excel로 저장시 파일 명을 지정한다.
excel = pd.read_excel('data/seoul_transportation.xlsx', sheet_name='철도', engine='openpyxl')
excel.head()-index=Frame옵션은 가급적 꼭 지정하는 옵션, 지정안하면 index까지 저장됨.
excel.to_excel('sample1.xlsx', index=False, sheet_name='샘플')-sheet_name을 지정하여, 저장할 시트의 이름을 변경할 수있음.
excel.to_excel('sample1.xlsx', index=False, sheet_name='샘플')여러 개의 시트에 저장하기 위해서는 ExcelWriter를 사용
pd.read_excel의 경우 읽기 형식이므로
excel = pd.read_excel('data/seoul_transportation.xlsx', sheet_name='철도', engine='openpyxl')
excel.to_excel(writer, index=False, sheet_name='샘플1')
excel.to_excel(writer, index=False, sheet_name='샘플2')
excel.to_excel(writer, index=False, sheet_name='샘플3')이 코드의 경우 샘플3의 sheet만 남게 됨
시트 불러오기
excel = pd.read_excel('data/seoul_transportation.xlsx', sheet_name='철도', engine='openpyxl')
writer = pd.ExcelWriter('sample2.xlsx')
excel.to_excel(writer, index=False, sheet_name='샘플1')
excel.to_excel(writer, index=False, sheet_name='샘플2')
excel.to_excel(writer, index=False, sheet_name='샘플3')
writer.close()그렇기에 ExcelWriter을 사용해 주어야 함.
df1 = pd.read_excel('data/seoul_transportation.xlsx', sheet_name='철도', engine='openpyxl')
df2 = pd.read_excel('data/seoul_transportation.xlsx', sheet_name='버스', engine='openpyxl')
sample=pd.ExcelWriter('sample.xlsx')
df1.to_excel(sample,index=False,sheet_name='철도')
df2.to_excel(sample,index=False,sheet_name='버스')
sample.close()*위 코드는 서로 다른 데이터 프레임을 모아 하나의 엑셀파일로 구성하는 코드이다

CSV(Comma Seperated Values)
-한 줄이 한 개의 행에 해당하며, 열 사이에는 쉼표(,)를 넣어 구분한다.
-Excel보다는 훨씬 가볍고 차지하는 용량이 적기 때문에 대부분의 파일 데이터는 CSV형태로 제공된다.
CSV-불러오기
df = pd.read_csv('data/seoul_population.csv')때때로 한글 데이터를 불러올때 다른 인코딩을 사용해야 하는 경우도 있다. 그럴때 encoding 옵션을 지정해주면 된다.
df = pd.read_csv('data/seoul_population.csv', encoding='utf8')가끔 utf8이 안될경우도 있다. 'euc-kr', 'cp949' 로 바꿔보면 대부분 해결이 된다.
CSV-큰 파일 데이터 끊어서 불러오기
-데이터의 크기가 매우 큰 경우 memory에 한번에 로드할 수 없다.
-chunksize를 지정하여 데이터를 끊어서 처리할 수 있다.
ex)chunksize=10 : 10개의 데이터를 로드한다.
df = pd.read_csv('data/seoul_population.csv', chunksize=10)10개의 행씩 끊어서 불러오는 코드
for d in df:
display(d)
CSV-저장하기
-저장하는 방식은 excel과 동일하다, 하지만 sheet_name 옵션은 존재하지 않는다.
-to_csv()로 csv파일 형식을 저장할 수 있다.
#csv파일 불러오기
df = pd.read_csv('data/seoul_population.csv')
#csv파일 저장하기, index=false로 지정함으로써 인덱스 값까지 저장되지 않도록했다.
df.to_csv('sample.csv', index=False)*읽어들인 Excel 파일도 CSV파일로 저장이 가능하다.
#excel파일로 불러오기
excel = pd.read_excel('data/seoul_transportation.xlsx', sheet_name='버스', engine='openpyxl')
#csv파일로 저장하기.
excel.to_csv('sample1.csv', index=False)
'Data-Analysis > Pandas' 카테고리의 다른 글
| Pandas(데이터 구조 살펴보기) (0) | 2022.10.11 |
|---|---|
| Pandas(DataFrame) (0) | 2022.10.11 |
| Pandas(Series, Indexing) (0) | 2022.10.11 |


