개요
pandas는 관계형 또는 레이블된 데이터로 쉽고 직관적으로 작업할 수 있돌고 설계되었고, 유연한 데이터 구조를 제공하는 Phthon패키지 이다.
또한 어떤 언어로도 사용할 수 있는 가장 강력하고 유연한 오픈 소스 데이터 분석/조직 도구이다.
Pandas는 다음의 종류의 데이터에 적합하다.
- SQL테이블 또는 Excel 스프레드 시트에서와 같은 열과 행으로 이루어진 정형 데이터
- 정렬되고 정렬되지 않은 시계열 데이터
- 다른형태의 관찰/통계 데이터 세트
*시계열 데이터는 일정 시간 간격으로 한 줄로 배열된 데이터를 의미(주식 데이터)
Pandas의 자료구조
Pandas의 자료 구조로 크게 3가지만 알면 된다.
- 1차원 자료 구조(1D): Series
- 2차원 자료 구조(2D): Dataframe
- 3차원 자료 구조(3D):Pannel
*사실상 Pannel까지는 잘 안다루게 된다.(시각적으로 보기 안좋음)
1)Series
-데이터를 담는 차원 배열 구조를 가진다.
-인덱스를 사용한다.
-데이터 타입을 가진다.
#numpy array 로 생성하는 경우
arr = np.arange(100,105)
arr
사진 설명을 입력하세요.
s = pd.Series(arr)
s*둘다 1차원 배열이며, numpy배열을 Series함수의 파라미터에 넣어주면 다음과 같은 결과가 출력된다.

사진 설명을 입력하세요.
*인덱스(0,1,2,3,4)가 포함되어 출력되었고, 하단에 데이터 타입을 같이 출력한다. 넘파이에 비해 예쁜 출력을 가진다.
데이터 타입 지정해주기.
#dtype을 지정하는 경우
s=pd.Series(arr,dtype='int32')
s*Series의 파라미터에 원하는 데이터 타입을 같이 넣어준다면 원하는 데이터 타입으로 지정이 가능하다.

사진 설명을 입력하세요.
numpy 배열이 아닌 일반 배열로 Series 생성하기.
s = pd.Series(['부장', '차장', '대리', '사원', '인턴'])
s*꼭 numpy배열을 넣어야 할 필요는 없다. 문자열로 생성한다면 dataType은 object로 나오게 된다.
*파이썬의 경우 문자열을 string이라고 하는데, 그와 같은 것이라고 보면 된다.

사진 설명을 입력하세요.
다양한 타입의 데이터를 섞은 경우.
s = pd.Series([91, 2.5, '스포츠', 4, 5.16])
s*다양한 데이터 타입의 데이터로 생성할 경우, object 타입으로 생성된다.

사진 설명을 입력하세요.
*다양한 데이터로 생성할 경우 가장 넓은 개념의 데이터 타입으로 생성된다.(int<float<object)
인덱스
s.index*기본 인덱스는 0부터 숫자형 index가 부여되는 RangeIndex로 생성된다.
*Range Index는 범위 안에 있는 숫자로 인덱싱이 가능하다.

0부터 5까지의 인덱스, 간격은 1을 가짐.

사진 설명을 입력하세요.
*0-5의 인덱스를 가지므로 음수의 인덱싱은 불가능하다.
기본 값으로 부여되는 RangeIndex에 사용자 정의의 Index를 지정할 수 있다.
s = pd.Series(['마케팅', '경영', '개발', '기획', '인사'], index=['a', 'b', 'c', 'd', 'e'])
s*index는 기본으로 주어지는 RangeIndex가 아닌 새롭게 부여된 Index로 덮여 씌여진다.

사진 설명을 입력하세요.

사진 설명을 입력하세요.
*또한, 새롭게 부여된 index로 인덱싱이 가능하다.
*하지만 숫자로도 인덱싱이 가능하다.

사진 설명을 입력하세요.

사진 설명을 입력하세요.
음수 인덱싱
*우리가 기본으로 부여된 숫자형 RangeIndex의 경우 음수로 인덱싱이 불가능했지만, 우리가 임의로 인덱스를 부여했을 경우.
음수로도 인덱싱이 가능하며 음수로 접근할 경우 파이썬의 배열의 음수 접근 방식과 비슷하다.

사진 설명을 입력하세요.
Series를 먼저 생성한 후 나중에 index를 부여할 수 있다.
s = pd.Series(['마케팅', '경영', '개발', '기획', '인사'])
s.index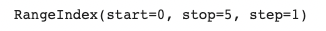
사진 설명을 입력하세요.
s.index = list('abcde')
s.index
사진 설명을 입력하세요.
*단, 지정하는 index의 개수가 데이터의 개수와 맞아야 한다.
값 만 출력.
s.values
사진 설명을 입력하세요.
*Series의 데이터 값만 numpy array 형식으로 가져온다.
차원 출력.
s.ndim
사진 설명을 입력하세요.
*.ndim은 데이터의 자료구조(차원)을 출력해 준다.
데이터의 개수
*shape은 데이터의 모양을 알아보기 위하여 사용하는데, Series의 shape은 데이터의 개수를 나타낸다.
튜플 형식으로 출력된다.
s.shape
사진 설명을 입력하세요.
*튜플 형식으로 출력이 되어야 하기 때문에 (5)로 출력된 것이 아니라(5,)로 출력이 된것이다.
(실제로 (5)의 데이터 타입을 뽑아보면 INT로 출력된다.)
NaN
-Pandas에서 NaN은 비어있는 데이터, 결측치를 의미한다.
-임의로 비어있는 값을 대입하고자 할때는 np.nan(numpy의 nan임)을 입력한다.
s = pd.Series(['선화', '강호', np.nan, '소정', '우영'])
s
사진 설명을 입력하세요.
다양한 Indexing
1.Fancy Indexing
-index를 선택하여 list로 정의하고, 선택한 index list로 indexing 하는 방법이다.
s = pd.Series(['손흥민', '김연아', '박세리', '박찬호', '김연경'], index=['a', 'b', 'c', 'd', 'e'])
s[['a','c']]

사진 설명을 입력하세요.
아니면 새로운 배열에 선택한 index를 넣어 생성하는 방법도 있다.
i = ['a', 'c']
s[i]
사진 설명을 입력하세요.
2.Boolean Indexing
-index list에서 True인 index만 선택한다. boolean index list 개수와 Series개수가 맞아야 한다.
-Series안에 boolean index를 넣는다고 생각하면 된다.
s[[True, True, False, False, True]]
사진 설명을 입력하세요.
i = [True, True, False, False, True]
s[i]
사진 설명을 입력하세요.
*하지만 각각의 인덱스 하나하나에 boolean 값을 지정해주기엔 매우 비효율적이다.
그렇기에 조건을 걸어서 boolean index list를 먼저 만들어 준 뒤 대입을 할 수 있다.
s = pd.Series([29, 99, np.nan, 11, 56], index=['a', 'b', 'c', 'd', 'e'])
s[s > 50]
사진 설명을 입력하세요.
*다중 조건의 경우 and,OR를 사용한다.
s[(s > 50) & (s < 80)]
사진 설명을 입력하세요.

사진 설명을 입력하세요.
*조건이 복잡할 경우 boolean index list를 따로 분리시켜 준다.
cond = (s > 50) & (s < 80)
cond
사진 설명을 입력하세요.
s[cond]
사진 설명을 입력하세요.
NaN값 처리
NaN값 찾기(isnull()과 isna())
-이 두함수의 결과는 동일하다.
-boolean Series를 리턴시킨다.
s.isnull()s.isna()
사진 설명을 입력하세요.
*Nan값만 걸러내기
s[s.isnull()]
사진 설명을 입력하세요.
NaN이 아닌 값 찾기(notnull()과 notna())
-이 두함수의 결과는 동일하다.
-boolean Series를 리턴시킨다.
s.notnull()
s.notna()
사진 설명을 입력하세요.
*NaN 아닌 값만 걸러내기
s[s.notnull()]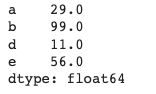
사진 설명을 입력하세요.
Slicing
-숫자형 index로 접근할 경우 ([a:b]), 뒷 인덱스(b)가 포함되지 않는다.
s[1:3]
사진 설명을 입력하세요.
*하지만 새롭게 지정한 인덱스는 시작, 끝 index 모두 포함된다.
s['a':'c']
사진 설명을 입력하세요.
'Data-Analysis > Pandas' 카테고리의 다른 글
| Pandas(데이터 구조 살펴보기) (0) | 2022.10.11 |
|---|---|
| Pandas(Excel, CSV 파일 불러오기) (1) | 2022.10.11 |
| Pandas(DataFrame) (0) | 2022.10.11 |


