역전파
- 모델내부의 파라미터의 최적화는 미분의 성질과 연쇄법칙(Chain rule)을 기반으로 한 역전파를 통해 진행된다.
- 역전파는 모델이 복잡할 수록 계산 과정이 복잡해져 코드를 직접 구현하기에는 어려움이 있다.
- 하지만 파이토치에는 간단하게 사용할 수 있는 다양한 최적화 방법을 제공하고 있다.
1. 그레디언트 텐서
- 일반적으로 인공 신경망의 최적화는 손실 함수의 최솟값(Global minimum)이 나오게 하는 신경망의 최적 가중치를 찾는 과정이다.
- 따라서 최적화를 위해 변화량을 나타내는 미분은 필수적인 요소이다.
- 인공신경망의 구조는 다음과 같이 입력 값이 들어와 여러 레이어를 지나 출력 값을 산출하는 합성 함수의 형태이다.
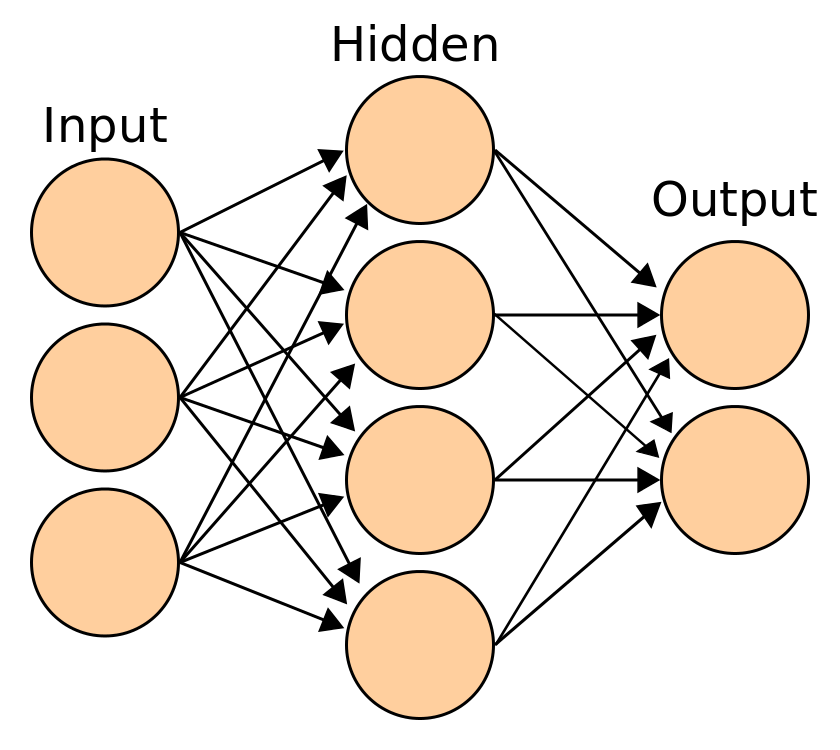
- 따라서 연쇄법칙을 통해 원하는 변수에 대한 미분값을 구할 수 있다.
import torch
x = torch.ones(2,2, requires_grad = True)
y = x+1
z = 2*y**2
r = z.mean()
print("Result:", r)- requires_grad = True는 해당 텐서를 기준으로 모든 연산들을 추적하여 그래디언트를 계산할 수 있게 한다.
- 즉 x에 대해 연쇄 법칙을 이용한 미분이 가능하다는 것이다.'
2. 그레디언트 텐서
- 일단 r를 기준으로 역전파를 진행해보자.
- 아래 코드는 $\frac{dr}{dx}$를 의미한다.
r.backward()
x.grad
output:
tensor([[2., 2.],
[2., 2.]])- 고급 코딩으로 가게 되면 이렇게 하나씩 그레디언트를 구해야 하는 일이 찾아온다. 하지만 지금은 이 방식에 대한 깊은 이해 보다는.
- 이러한 컨셉으로 역전파를 진행한다는 점을 이해하는 것에 중점을 두자.
3. 자동 미분 - 선형 회귀식
- x를 입력값, y를 실제 값이라고 하였을 때, 가중치 w와 b를 loss 값을 감소시키는 방향으로 100번 동안 학습하는 과정을 코드로 구현해 보겠다.
입력값, 실제 값 정의
- 우선 입력값 x와 실제 값 y를 정의해준다.
import torch
from matplotlib import pyplot as plt
x = torch.FloatTensor(range(5)).unsqueeze(1)
y = 2*x + torch.rand(5,1)
num_feature = x.shape[1]- torch.FloatTensor는 리스트 range(5)를 이용해 텐서로 만든다.
- 이때 원래 크기는 1차원(torch.Tensor(5))이라서 행렬 계산을 위해 5,1로 만들어 주어야 한다.
- 그러기 위해 unsqueeze(1)를 사용해서 1번째 위치의 차원을 늘려주는 역할을 하여 최종적으로 x의 크기는 torch.Size(5,1)이 된다.
(만약 unsqueeze(0)을 하면 (1,5)가 되겠지?)
- y는 실제값으로 임의의 값을 만들어 주자.
가중치와 바이어스 정의
w =torch.randn(num_feature, 1, requires_grad=True) # 가중치
b =torch.randn(1, requires_grad=True) # 바이어스- 선형 식은 $y = wx + b$로 표현된다.
- 바이어스는 모든 인스턴스에 동일한 숫자를 더해주는 것이므로 크기가 1인 텐서로 정의된다.
입력값 과 실제값 x와 y는 변하지 않은 값으로서 업데이트가 필요하지 않은 반면,
w,b값은 역전파를 통해 최적값을 찾는 것이므로 w, bd에 requires_grad를 True로 활성화 시킨다.
학습률, 옵티마이저 정의
- 옵티 마이저는 모델을 학습시키는 과정에서 사용되는 최적화 알고리즘이다.
- 모델이 예측한 출력값과 실제 정답의 차이를 최소화하는 방향으로 모델읠 가중치(weight)와 편항(bias)를 업데이트하여 학습이 진행된다.
- 가중치를 업데이트하는 최적화 방법은 매우 다양하다.
- 그중 가장 널리 사용되는 방법이 경사 하강법이다.
- 이 예시에서는 확률적 경사하강법SGD를 사용한다.
경사 하강법 : 목적 함수인 손실 함수를 기준으로 그래디언트를 계산하여 변수를 최적화하는 기법이다.
learning_rate = 1e-3
optimizer = torch.optim.SGD([w,b], lr=learning_rate)
학습
loss_stack = [] #에포크마다 loss값을 저장하는 리스트
for epoch in range(1001): # epoch = 1001
optimizer.zero_grad() # 최적화 과정에서 누적된 값 초기화
y_hat = torch.matmul(x,w) + b # 선형식
loss = torch.mean((y_hat - y) ** 2) # 손실 함수 계산(여기서는 MSE)
loss.backward() # 역전파의 기주을 손실함수로
optimizer.step() # optimizer로 최적화
loss_stack.append(loss.item()) #loss값 저장.
if epoch % 100 == 0: # 에포크가 100번 누적될때마다 loss값 출력
print(f'Epoch {epoch}:{loss.item()}')학습된 모델로 예측값 산출
- with torch.no_grad():를 이용하여 requires_grad가 작동하지 않도록 한다.
with torch.no_grad():
y_hat = torch.matmul(x,w) + b
Output:
tensor([[1.0460],
[2.8785],
[4.7109],
[6.5433],
[8.3758]])
시각화
plt.figure(figsize=(10, 5))
plt.subplot(121)
plt.plot(loss_stack)
plt.title("Loss")
plt.subplot(122)
plt.plot(x, y,'.b') # 실제 값
plt.plot(x, y_hat, 'r-') # 예측 값
plt.legend(['ground truth', 'prediction'])
plt.title("Prediction")
plt.show()