Argmax란?
Argmax는 ML에서 주로 접할 수 있는 수학 함수이다.
예를 들어, 알고리즘을 설명하는데 사용되는 연구 논문에서 argmax가 사용되는것을 볼 수 있다.
알고리즘 구현에서 argmax function을 사용하도록 지시받을 수도 있다.
그렇다면 argmax는 무엇이며, 어떻게 작동하는 것일까??
1. Armax는 파라미터로 받아오는 배열에서 최대값을 가지는 값의 인덱스를 리턴하는 함수이다.
2. Argmax는 예측 확률이 가장 큰 클래스를 찾기 위해 기계 학습에서 가장 일반적으로 사용된다.
3. Argmax는 직접 구현할 수 있지만, 실제로 Numpy 라이브러리의 argmax() 함수를 주로 사용한다.
Argmax의 기본적인 예시를 들어보자면 다음과 같다.
- 우선 0~9까지의 배열을 생성한다.
import numpy as np
list_a = np.arange(10)
print(list_a)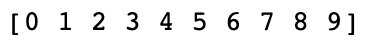
- 다음 배열에서 최댓값은 9이고, 최댓값을 가지는 인덱스는 10임을 알 수 있다.
- 그렇다면 다음 배열을 랜덤으로 섞어보겠다.
import random as rand
rand.shuffle(list_a)
print(list_a)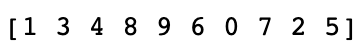
- 여기서 최댓값을 가지는 9의 인덱스는 무엇일까? 아마 인덱스 값을 찾을 수 있겠지만 처음에 비해 시간이 좀 걸릴것이다.
- 게다가 10개의 숫자가 아닌 1000개 10000개의 값을 가지는 배열에서 최댓값을 가지는 인덱스를 찾기 위해 하나씩 비교하는것은 너무나 시간 낭비이다.
- 그래서 argmax() 를 사용하는 것이다.
np.argmax(list_a)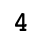
- argmin()은 반대로 배열에서 최솟값의 인덱스를 찾아주는 함수이다.
np.argmin(list_a)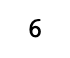
머신러닝에서는 Argmax가 어떻게 사용될까?
- 케라스에는 predict()라는 메서드가 존재한다.
- 이는 주어진 검증 데이터에 대한 출력층의 출력 개수 확률값을 리턴한다.
- 무슨 말인지 나도 잘 모르겠으니까 실습을 통해 이해해 보자
- 우선 예시로 mnist 데이터를 불러온다.
import tensorflow as tf
(train_images, train_labels), (test_images,test_labels)= tf.keras.datasets.mnist.load_data()
# 데이터 전처리
train_images = train_images.astype('float32') / 255.0 # 이미지의 픽셀값을 0~255에서 0~1사이로 변환(정규화)
test_images = test_images.astype('float32') / 255.0- 우리가 이번 시간에 다룰 데이터는 검증 데이터로 사용될 test_images이다.
- test_images의 데이터 형태는 다음과 같다.
test_images.shape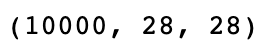
- 우리가 심층 신경망 모델을 미리 설계 했고 학습까지 완료했다고 가정했을때, 모델을 통해 검증데이터(test_images)가 무엇인지 예측하기 위해 predict() 메서드를 사용한다.
- 우리가 사용할 모델의 구조는 다음과 같다.

- 출력층에서 출력 뉴런의 개수는 10개인것을 알 수 있다. 즉 predict()를 이 모델에 적용하게 되면 10개의 클래스에 대한 확률을 반환한다.
- 즉 검증 샘플 1개 (1,28,28)의 라벨 값들에 대한 확률값을 리턴한다.

- 테스트 데이터의 샘플 개수는 10,000개이기 때문에 predict()는 (10,000, 10)크기의 배열을 리턴한다.
new_model.predict(test_images).shape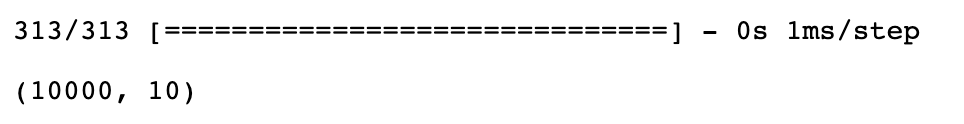
- argmax는 샘플 1개에 대한 예측값중 가장 큰 예측값의 인덱스를 찾기 위해 사용된다.
import numpy as np
val_labels = np.argmax(new_model.predict(test_images),axis=-1)
print(np.mean(val_labels==test_labels))- argmax를 통해서 확률 값이 가장 높을 라벨을 예측 라벨로 지정하고 예측 라벨을 실제 라벨과 비교하여 정확도를 계산할 수 있게 된다.